
3- Il existe un troisième niveau plus précis encore que le deuxième ; on y trouve par exemple comme « sous-sous discipline » d’histoire : histoire militaire, histoire des femmes, histoire européenne… et comme sous-sous-discipline d’informatique, systèmes de stockage des données, architecture des ordinateurs et des systèmes, etc.
On peut penser que ces sous-sous-disciplines correspondent assez bien à des départements d’universités.
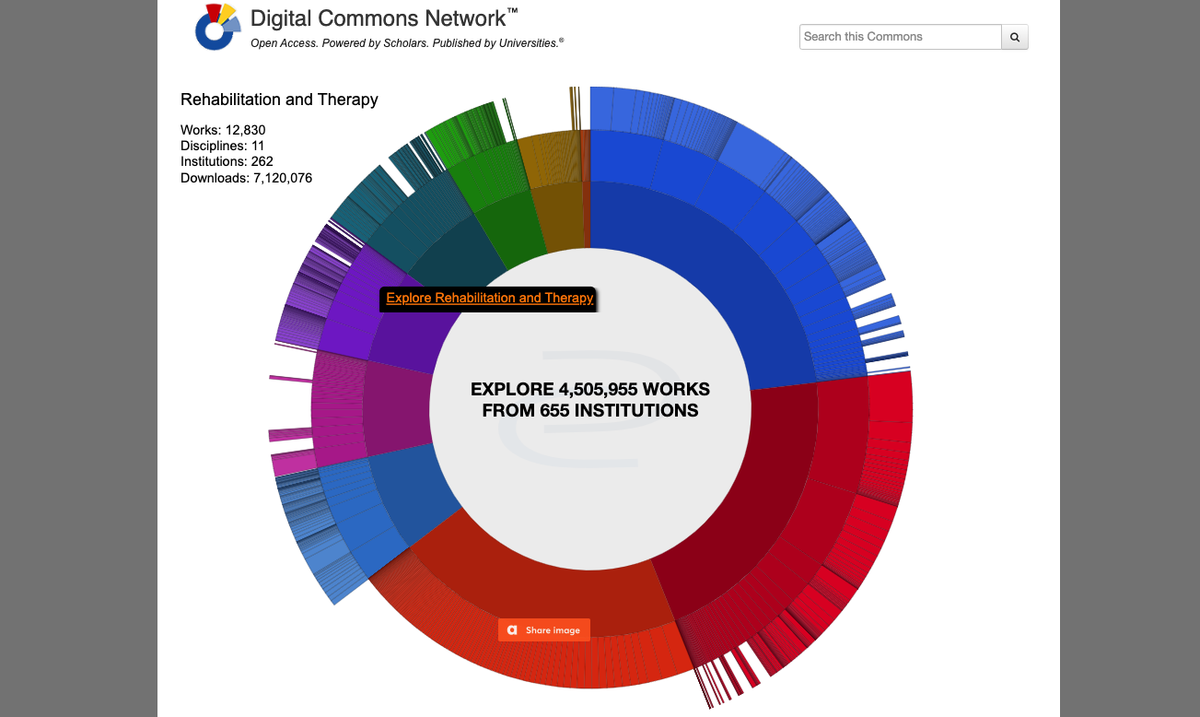
Ce qui est très original dans ce site est que si l’on clique sur une partie de la roue, quel que soit le niveau, apparaît une page avec les références des documents les plus « populaires » de cette partie de roue. Sont ainsi affichées les références des documents les plus téléchargés pendant un mois calendaire (précisons que lors de nos tests, c’était l’avant-dernier mois qui était pris en compte), puis les références des articles les plus récents, ainsi que le nombre total de ces documents, le tout dans le format titre, auteur(s), affiliation.
Si l’on dispose d’un compte, on peut mettre en place une veille pour les références apparaissant dans cette thématique.
Une surveillance « en live »
Ce qui est franchement divertissant est que, au-dessus des références figure une carte du monde où apparaissent en temps réel, une fois que l’on est connecté à la page, des points sur cette carte et au-dessus, au même moment, la ville et le pays de la personne qui télécharge un article de cette catégorie dont le titre apparaît ainsi que l’affiliation des auteurs.
Si la recherche par thématique est proposée avec une approche originale, la recherche par mot clef est réduite à sa plus simple expression puisque l’on ne dispose, dans la page d’accueil générale, que d’une boîte de recherche.
● Nos tests semblent montrer que les opérateurs AND et OR fonctionnent, de même que la possibilité de chercher sur une expression mise entre guillemets.
● En revanche, on ne dispose pas d’opérateurs de proximité ni de recherche sur un champ donné. En effet, le système cherche sur tous les champs y compris les références, les légendes des figures et le texte intégral ce qui nuit fortement à la précision de la recherche. On peut néanmoins améliorer la précision en recherchant sur la discipline/sous-discipline/sous-sous-discipline à laquelle on s’est connecté.
● Les résultats, dont le total apparaît en haut de l’écran, apparaissent en ordre antéchronologique.
● Pour chaque résultat, on trouve le titre, l’auteur/les auteurs, la date de chargement et la date de publication.
Si l’on met la souris sur le titre, apparaît en plus la source, l’abstract s’il existe, et un lien vers le document. Un clic sur le lien envoie sur une page de l'université qui propose le document avec un lien pour le télécharger.
À gauche de la liste de résultats figure une analyse quantitative des résultats selon différents critères : discipline, institution, année de publication et publication.
Dans un premier temps, on trouve cinq termes pour chaque critère et si l’on en demande plus on arrive à 30 qui est la limite.
Mais l’ennuyeux est que l’on ne peut sélectionner qu’un terme à la fois puisque cette sélection déclenche la recherche.
Une recherche élargie et avancée sur chaque site d’université
Dès que l’on fait le choix de télécharger un document, on arrive sur le site d’une université.
● On a alors la possibilité d’utiliser une recherche avancée, par champ et par date. On peut entrer des termes dans une ou plusieurs boîtes combinées avec les opérateurs AND, OR ou NOT. On dispose de deux troncatures, l’une d’un caractère, l’autre illimitée. Ces troncatures peuvent être situées à la fin d’un mot ou à n’importe quel endroit à partir de la deuxième lettre. On dispose aussi d’une recherche floue (fuzzy search), mais pas d’opérateurs de proximité.
● On peut rechercher soit dans la publication d’où est extrait le document, soit sur l’ensemble des repositories de cette université, soit, troisième option, sur l’ensemble des repositories des 655 universités. La recherche se fait alors sur 7,94 millions de documents. La différence avec 4,5 millions est constituée de documents qui sont référencés, mais pour lesquels on ne dispose pas d’un lien vers le déchargement gratuit du document.
Un contenu assez original
Un rapide test sur quelques thèses nous ont fait apparaître que la plupart des thèses présentes dans Digital Commons Network n’étaient pas disponibles sur les sites classiques de thèses (NDLTD, OATD, BASE).
Tests : Sur un très petit échantillon de six références d’articles, une était à la fois sur Scopus, Dialog et Google Scholar, une autre sur Dialog seulement et une autre, enfin, dans Google Scholar uniquement.
Par ailleurs on trouve le fac-similé de quotidiens très anciens, remontant, par exemple, à la fin du XIXème siècle.
Bien que ces tests n’aient aucune prétention à la représentativité, ils semblent montrer qu’une bonne partie du contenu de Digital Commons Network est original.
C’est donc une source intéressante à prendre en compte même si la recherche se fait de façon un peu inhabituelle avec une logique particulière.
Digital Commons Network utilise les fonctionnalités mises à disposition par bepress.
Bepress a été créé en 1 999 sous le nom de Berkeley Electronic Press par trois professeurs de cette université californienne pour faciliter la communication des informations produites par les universités.
Elle a été rachetée par Elsevier en 2017.