
Cette approche est intéressante :
- Une grande quantité d’articles et de références diverses transitent via les réseaux sociaux, facilitant la découverte d’experts et de sources de qualité. Elles donnent également accès à des médias qui y (re)publient leurs articles ;
- Un logiciel d’analyse de réseau puissant tel que Gephi peut, dans une masse de données, faire émerger des acteurs, des liens et leur donner du sens ;
- Twitter est le réseau social qui, avec LinkedIn, contient le plus d’informations économique et sectorielle, et c’est à ce jour le seul qui soit réellement ouvert en termes de récupération de données.
Les données a priori pertinentes à extraire de Twitter pour identifier des sources d’information sont :
- Les comptes de médias - très nombreux et de nature diverse sur Twitter ;
- Les comptes de spécialistes/influenceurs partageant de l’information et des sources
- Les tweets de la communauté concernée, contenant a priori des liens d’intérêt.
La méthodologie à mettre en œuvre consistera en deux étapes : tout d’abord, l’extraction d’un flux de données pertinent et complet depuis Twitter, en utilisant un scraper intégré dans une plateforme de surveillance des réseaux sociaux ou utilisé de manière autonome, puis la production et le formatage des données, qui seront importées dans le logiciel de datavisualisation, ici Gephi, pour y être analysées.
Cependant, les premiers tests montrent des difficultés insoupçonnées au départ.
La première difficulté est la récupération des données Twitter. En effet, si l’on utilise l’un des nombreux outils de scraping disponibles sur le marché, on se rend compte que la collecte de données gratuites de la timeline est limitée à une période de sept à neuf jours dans le cadre de la politique de l’API de Twitter. Une contrainte qui ne va pas s’arranger avec la mise en œuvre de la récente décision d’Elon Musk de rendre payant l’accès à l’API. Il est à craindre qu’elle affectera le prix, voire l’avenir de ces solutions.
Cette restriction peut être très gênante car le nombre de tweets susceptibles d’être récupérés dépend de la popularité du sujet au sein des communautés actives. Ainsi, pour un sujet qui n’est pas au centre de l’actualité, on risque de récupérer très peu de tweets, comme c’est le cas pour notre sujet de la santé numérique.
Précisons que les scrapers nécessitent souvent des compétences avancées en langage de programmation (comme Python) et les fonctionnalités les plus utiles sont payantes, avec un flou avéré sur le requêtage dans l’outil.
Pour surmonter ces difficultés, il est possible de recourir à des solutions intégrées de veille sur les réseaux sociaux telles que Visibrain ou Digimind. Celles-ci permettent d’accéder à l’historique complet des données sur une interface utilisateur conviviale, tout en offrant des options avancées de requêtage pour collecter, extraire et analyser les données des réseaux sociaux.
Il faudra néanmoins garder à l’esprit que le téléchargement des historiques de données a un coût non négligeable. Nous mettrons en relation ce problème avec celui de l’accès général aux données, qui nécessitent toujours des outils professionnels payants pour être récupérées. Une problématique similaire à celle des articles de presse, décrite dans l’article de Carole Tisserand Barthole dans ce numéro.
La deuxième difficulté est liée au traitement du flux de données extrait de Twitter, qui le plus souvent sera totalement déstructuré et qu’il faudra nettoyer et reformater en fonction de l’outil de datavisualisation dans lequel il sera importé. Gephi demande une structuration experte des données : un outil de cartographie de réseau s’appuie sur des «nœuds» (ou nodes) qui représentent les entités ou les acteurs du réseau (personnes, organisations, concepts ou des événements) et des liens ou arêtes (edges) qui représentent les relations entre ces entités. La grande difficulté sera de savoir, dans la masse informe des données primaires, quels éléments extraire et comment les mettre en relation en fonction de l’objectif de l’analyse défini au départ.
Pour contourner ce problème, on aura tendance à privilégier des outils comme Socioviz ou Visibrain, qui offrent tous deux une exportation des flux formatés en CSV ou GEFX, lisibles par Gephi.
- Socioviz (freemium) a malheureusement beaucoup de limites liées à son coût relativement modeste, mais il a la particularité d’avoir intégré dans son interface une analyse et visualisation relationnelle ergonomique et attrayante.
- L’intégration développée par Visibrain avec Gephi permet de traiter toute la chaîne de valeur, depuis la mise sous surveillance et l’export de données structurées (hashtags et comptes d’utilisateurs) dans les bons formats, permet de récupérer le graphe généré dans Gephi pour être intégré dans la production de rapports d’analyse en ligne (smartboard). On rappellera l’excellent site Cartorezo de Guillaume Sylvestre qui permet de découvrir tout le potentiel d’un rapport analytique.
Enfin, la dernière difficulté, la plus fondamentale, réside dans le choix du type de cartographie adapté.
Si nous revenons à notre exemple d’identification de nouvelles sources dans le secteur de la santé numérique, l’utilisation de Gephi se révèle très pertinente pour la détection et la visualisation des comptes d’utilisateurs ou des comptes des médias importants. La cartographie de réseau permet de faire émerger et de hiérarchiser les comptes les plus représentatifs ou influents au sein d’une communauté fédérée par le thème de la santé numérique, grâce à l’analyse des relations entre les comptes.
En revanche, l’usage de la cartographie par analyse relationnelle de réseau sera inutile pour faire émerger - et représenter par la même occasion - les liens vers les médias mentionnés dans les tweets des uns et des autres. Il faudra plutôt extraire et représenter très classiquement une série de noms de domaine, comme le fait raisonnablement bien sur les huit derniers jours - modestement certes vu la richesse des données potentiellement disponibles - le logiciel gratuit Social Bearing (https://socialbearing.com/). (cf. Figure 1). En beaucoup plus puissant et sur une période historique de son choix, on les fera émerger sur Visibrain, où tous les liens Twitter sont vus en étendu (cf. Figure 2).
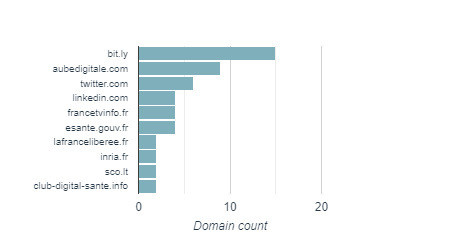
Figure 1 : Top sites extraits sur SocialBearing
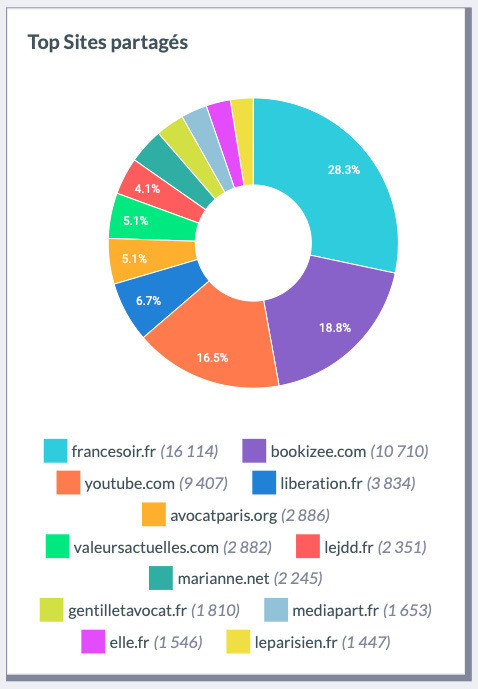
Figure 2 : Top Sites extraits sur Visibrain
ZOOM SUR GEPHI
La compréhension de la structure et des relations d’un réseau passe par des séries d’opérations itératives et exploratoires, via des fonctionnalités qu’il faudra apprendre à maîtriser :
- Les algorithmes de spatialisation pertinents pour placer les différentes entités (les nœuds) sur le graphique et produire une représentation intelligente et lisible des relations et interactions ;
- Les fonctionnalités statistiques et de filtrage des données pour analyser les liens : calcul de mesures de centralité, détection de communautés et clusters, ainsi que de nombreuses fonctions graphiques avancées.
Soulignons que l’exploitation de toute la puissance de ce logiciel suppose un apprentissage rigoureux à partir de quelques sources disséminées sur le Web. On retiendra principalement :
- https://master-iesc-angers.com/outils/ ;
- https://docs.visibrain.com/docs/introduction-pourquoi-cartographier
- et les vidéos de Sébastien Montaufier dont voici un exemple https://www.youtube.com/watch?v=FxckuTRz0cg.
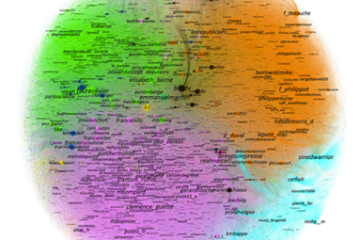
Et parce que l’image en dataviz vaut, souvent, mieux qu’un long discours, nous illustrerons via la représentation des données obtenue en première instance sur Gephi, à partir d›un flux Twitter proprement formaté récupéré sur la plateforme Visibrain, relatif au thème populaire des retraites (Cf. Figure 3) puis la représentation graphique experte (Cf. Figure 4) de l’analyste Thierry Herrant insérée dans son rapport (https://www.visibrain.com/fr/blog/reforme-des-retraites-sur-twitter-cinq-enseignements-a-tirer). Cette représentation, qui met en évidence les différentes communautés d’influence avant les grèves, montre que la maîtrise de la datavisualisation est primordiale.
Ci-dessous sur GEPHI :
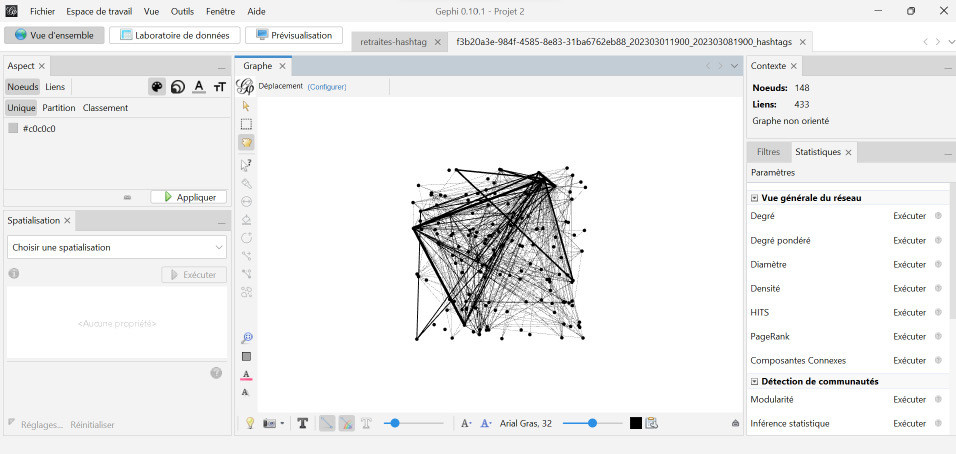 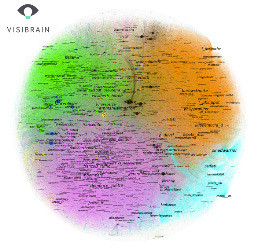 |
| Figure 3 : la récupération du flux à l’état «brut» sur Gephi Figure 4 : la mise en forme experte sur Gephi |