

Le cœur de la machine « Google » : un index gigantesque
Une couverture du Web inégalée
Sur son site, Google indique que :
« L’index de recherche Google contient des centaines de milliards de pages Web et sa taille est bien supérieure à 100 millions de gigaoctets. Dès que nos robots d’exploration détectent une page Web, nos systèmes la visualisent, comme avec un navigateur. Il ressemble à l’index que l’on peut trouver à la fin d’un livre, à la différence près qu’il recense chaque mot de chaque page Web. Lorsque nous indexons une page Web, nous l’associons aux entrées des différents mots affichés sur la page. »
On constate que cela fait des années que Google utilise les mêmes chiffres pour son index : on retrouve exactement les mêmes déclarations de Google en 2017, 2018, 2019, 2020 et 2021.
Il est donc impossible de savoir à quelle vitesse l’index de Google évolue et s’il grossit encore, ou si le moteur préfère aujourd’hui se concentrer sur la qualité plutôt que sur la quantité.
De façon générale, Google fournit de moins en moins de données et d’indicateurs sur l’indexation des pages et sur sa façon de travailler. Référencer son site web de manière optimale semble être devenu mission impossible…
Cela dit, ce qui est sûr, c’est qu’en termes de couverture du Web, personne n’égale Google aujourd’hui.
Les autres moteurs comme Bing, DuckDuckGo, Brave Search, etc. sont loin d’avoir une couverture aussi importante et les autres acteurs de la recherche d’information, notamment professionnels tels que les grands agrégateurs de presse ou plateformes de news par exemple, n’ont pas les moyens de gérer une quantité de sources et d’informations aussi importante.
Une couverture qui n’est pas exhaustive pour autant
Malgré un index titanesque, Google, pas plus que les autres acteurs, n’est en mesure d’indexer la totalité du Web.
Lors de la récente conférence Haystack qui s’adresse aux développeurs et informaticiens, un des intervenants indiquait que seule 1 page sur 3 000 en moyenne était indexée par les moteurs, dont Google, et qu’il est en réalité impossible pour un moteur d’indexer tous les mots de chaque page web (alors que le discours officiel de Google nous dit le contraire).
Un index qui n’est visible qu’en partie par l’internaute
Mais attention, avoir le plus gros index ne signifie pas non plus donner à l’internaute accès à toute cette richesse.
Google ne donne jamais accès à tous les résultats susceptibles de répondre à une requête, mais seulement à une sélection de résultats.
- Il y a une dizaine d’années, lorsqu’on lançait une requête, on pouvait accéder à 800/1000 résultats réellement accessibles et cliquables.
- Il y avait quelques années, on tournait autour de 200/300 résultats accessibles. Aujourd’hui on dépasse rarement les 100 résultats accessibles.
Exemple :
Une requête Coronavirus France lancée sur notre ordinateur ne génère par exemple que 78 résultats (Cf. Figure 1 – recherche sur Coronavirus France dans Google) ! Très improbable au regard de toute l’actualité sur le sujet au cours des deux dernières années…
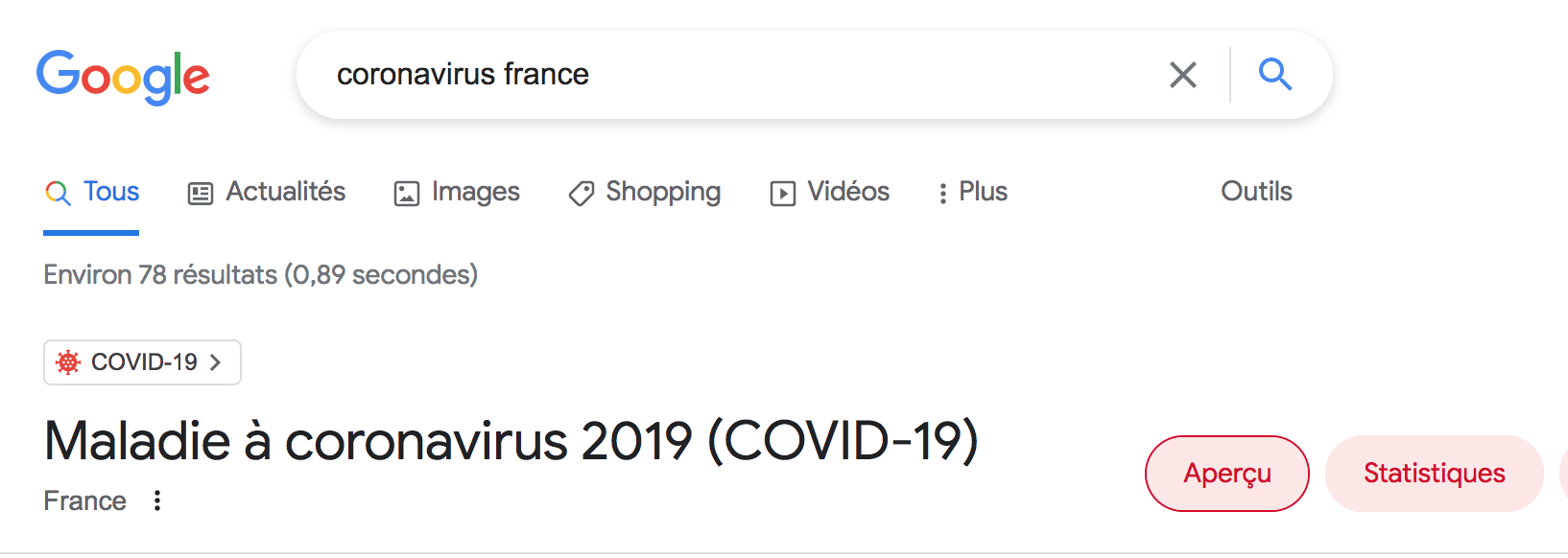
Figure 1. Recherche sur Coronavirus France dans Google
La même requête, avec cette fois-ci l’anglais comme paramètre de langage génère cette fois-ci 180 résultats pour la quasi-totalité en français (Cf. Figure 2. Recherche sur Coronavirus France en choisissant la langue anglaise) Surprenant ! Mais dès la deuxième page, les résultats s’avèrent complètement hors sujet : page d’accueil de Truffaut, Starbucks, Burger King, Banque Populaire, etc. On cherche toujours le rapport…
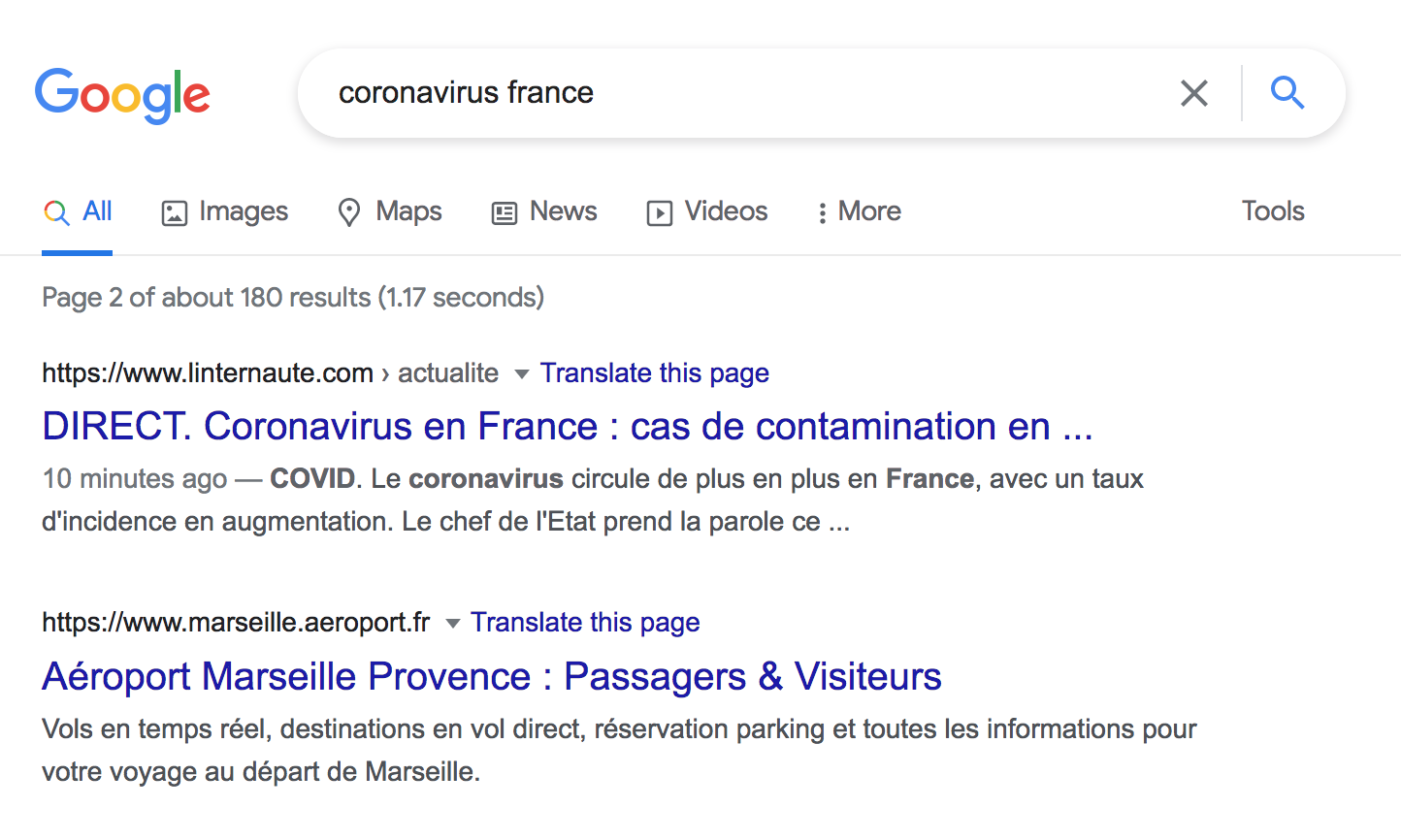
Figure 2. Recherche sur Coronavirus France en choisissant la langue anglaise
On notera également la présence de résultats qui n’ont rien à voir avec le sujet, mais sont visiblement liés à notre historique, nos goûts et notre localisation.
Avec un index aussi conséquent, Google est en principe capable de faire émerger des pages web que l’on a peu de chance de trouver ailleurs. Mais ce n’est pas parce que Google indexe une quantité phénoménale de contenus qu’il les fait nécessairement émerger et qu’il les affiche lors d’une recherche dans son moteur.
Et c’est là qu’on en vient à la question cruciale des algorithmes qui viennent déterminer ce qui apparaîtra ou non dans les résultats.
Des algorithmes de machine learning qui influent grandement sur les résultats
Au-delà de l’index, le cœur du réacteur de Google aujourd’hui, ce sont ses algorithmes dopés à l’IA et au machine learning.
La place du machine learning au sein des algorithmes
Le machine learning est utilisé à différents niveaux dans les moteurs de recherche et pas seulement chez Google.
- Pour la reconnaissance et détection de patterns ce qui permet d’identifier le spam et les contenus dupliqués ;
- Pour détecter de nouveaux signaux qui pourront être utilisés pour le classement des résultats ;
- Pour la compréhension du langage naturel ;
- Pour rechercher les images et comprendre ce que contiennent les images ;
- Pour améliorer la qualité des publicités et l’adéquation de leur affichage ;
- Pour identifier des synonymes et termes proches ;
- Pour essayer de comprendre et détecter l’intention de l’utilisateur.
Sur ce sujet, on conseillera la lecture de l’article « How Search Engines Use Machine Learning: 9 Things We Know For Sure » paru en août 2021 sur le Search Engine Journal, référence incontournable pour les professionnels du SEO.
Les différents algorithmes qui ont façonné Google hier et aujourd’hui
Depuis une dizaine d’années, Google annonce régulièrement des changements majeurs avec le lancement de nouveaux algorithmes. À chaque fois, ils viennent améliorer (du point de vue de Google) la recherche et font de Google ce qu’il est aujourd’hui.
On peut avoir le sentiment que chaque nouvel algorithme vient remplacer le précédent alors qu’en réalité, Google est aujourd’hui constitué de multiples algorithmes.
Pendant de nombreuses années, le fonctionnement de Google était assez simple et pour les créateurs de sites web, il s’agissait surtout de réussir à placer les bons mots-clés et avoir un netlinking (liens entrants et sortants) de qualité. Mais aujourd’hui le fonctionnement du moteur est tellement complexe qu’on a le sentiment que plus personne (même les experts SEO) ne sait précisément ce qu’il faut faire pour être bien positionné dans les résultats Google.
Le virage a commencé il y a une dizaine d’années quand Google a commencé à introduire de l’IA dans son moteur et sensiblement au même moment où il a commencé à utiliser un Knowledge Graph .
Sur ce sujet, voir notre article « Les Knowledge Graphs vont-ils enfin révolutionner la recherche d’information professionnelle ? » - BASES n° 394 – juillet/août 2021.
- En 2011, Google a lancé son algorithme Panda qui avait pour but de lutter contre le spam et les contenus dupliqués ;
- En 2012, la question du spam était encore au cœur de préoccupations de Google avec le lancement de Penguin qui essayait de repérer les sites qui avaient des backlinks suspects (achat de liens par exemple).
On voit bien que Google a commencé par essayer de faire le ménage dans son index et dans les résultats en éliminant tous les sites et pages web qui s’apparentaient à des spams. Et il faut bien avouer que depuis des années on ne voit plus apparaître de sites de ce genre dans Google, comme les pages qui listent uniquement des mots-clés populaires, mais qui n’ont aucun sens. Aujourd’hui les contenus qui apparaissent en premier ne sont pas nécessairement ceux qui mériteraient d’être mis en évidence, mais cette publicité masquée est faite avec beaucoup plus de panache et de subtilité.
- C’est aussi en 2012 que Google a intégré le Knowledge Graph à son moteur. C’est le moment où Google a commencé à essayer de comprendre ce que recherchait l’utilisateur sans rechercher « bêtement » des mots-clés. Le Knowledge Graph a permis de relier des mots-clés à des entités et ainsi désambiguïser les requêtes (Jaguar pour l’animal ou la marque de voiture par exemple).
- Le lancement de l’algorithme Hummingbird lancé en 2013 allait aussi dans ce sens avec pour but d’aider Google à interpréter la requête et en fournissant des résultats qui n’ont pas nécessairement les mots-clés dans la page. C’est le moment où Google a commencé à rechercher automatiquement sur les synonymes et termes/concepts proches.
Durant les années qui ont suivi, Google s’est ensuite centré sur d’autres thématiques.
2014 - PIGEON
L’algorithme Pigeon lancé en 2014 avait pour but d’améliorer les résultats locaux. À partir de 2015, Google a commencé à basculer de la recherche sur ordinateur (desktop) à la recherche mobile. Le mobile est devenu la priorité de Google. Pendant des années ont co-existé deux index, un pour les résultats sur desktop et un pour les résultats sur mobile. Depuis le début de l’année 2021, tous les sites sont passés sur l’index mobile et il faut donc que les sites soient optimisés en étant rapides et ergonomiques pour le mobile, au risque d’avoir une visibilité quasi nulle.
2015 - RANKBRAIN
La question de la compréhension de l’utilisateur est revenue sur le devant de la scène en 2015 avec le lancement de Rankbrain qui fait partie de l’algorithme Hummingbird et a permis d’aller plus loin dans cette direction. Même si personne ne sait ce qu’il y a précisément derrière cet algorithme, l’idée est que Google prend en compte les synonymes, les concepts implicites et l’historique de l’utilisateur pour lui proposer des résultats censés lui convenir.
2018 - MEDIC
En 2018, l’algorithme Medic a entraîné Google sur le chemin de la confiance et l’autorité des sites d’information. Selon plusieurs experts, cet algorithme aurait permis d’implémenter le concept du EAT (Expertise, Authority, Trust) qui existe dans ses guidelines depuis 2014. Pour qu’un site soit bien positionné, il faut qu’il ait une certaine popularité et notoriété, mais aussi de la légitimité.
2019 - BERT
Avec BERT en 2019, on revient de nouveau à la question de la compréhension de la requête de l’utilisateur avec cette capacité à interpréter le texte, identifier les entités et les relations entre ces entités, mais avec plus de finesse que ce que proposaient les précédents algorithmes (Hummingbird et Rankbrain).
2021 - MUM
Début 2021, Google annonçait une nouvelle avancée au niveau de ses algorithmes appelée « Passage Indexing ». Il s’agit d’une nouvelle technologie utilisée par Google qui permet de classer les passages individuels d’une page dans les résultats de recherche en fonction de la requête des utilisateurs. Cela fonctionne déjà aux États-Unis depuis février 2021 et pourrait impacter 7 % des recherches. Cela pourrait permettre de faire ressortir des contenus longs qui abordent différents sujets et qui ont actuellement du mal à ressortir, car Google juge et indexe l’intégralité d’une page.
Sur ce sujet, on conseillera la lecture d’une présentation appelée « Passage indexing is likely more important than you think » réalisée par l’experte SEO Dawn Anderson en août 2021.
Enfin au mois de mai dernier, Google a parlé de l’avenir de son moteur et d’un nouvel algorithme appelé MUM (Multitask Unified Model) qui serait capable de comprendre des requêtes de plus en plus complexes. Selon Google, le but serait de « transformer la recherche sur Internet en un service beaucoup plus sophistiqué, agissant comme un assistant virtuel de recherche qui fouille le Web pour trouver des solutions à des questions précises ».
D’après les premiers éléments annoncés par Google, MUM représenterait une avancée majeure :
- D’une part, il permettrait d’analyser et d’intégrer aussi bien des images que du contenu audio, vidéos et images.
- D’autre part, il serait en mesure de comprendre des besoins de plus en plus complexes et serait plus dans cette démarche « conversationnelle » sur laquelle Google travaille depuis des années (voir notre article « De la recherche classique à la recherche conversationnelle - Dossier spécial Search 2017 » - BASES n° 354 – décembre 2017). L’idée étant que le moteur garde une mémoire des besoins et questions antérieures de l’utilisateur comme le ferait un être humain.
- Enfin, il intégrerait enfin cette dimension multilingue où l’internaute cherche dans une langue, mais récupère des résultats pertinents dans d’autres langues.
D’après Google, MUM serait 1000 fois plus puissant que BERT. Reste à voir ce que cela donnera vraiment quand il sera implémenté dans le moteur.
Des algorithmes qui ont transformé Google en assistant virtuel
Les évolutions de la « salle des machines » de Google et notamment les évolutions majeures de ses algorithmes ont changé la nature profonde de Google.
Google est d’ailleurs le premier à le revendiquer : il y a quelques années, il avait lui-même annoncé qu’il était devenu un moteur de réponses et lors de sa récente conférence annuelle, il s’est défini lui-même comme un « assistant virtuel » en devenir.
La détection de l’intention de l’utilisateur a fait basculer Google dans le rôle d’assistant
Pour comprendre comment Google a pu passer d’un moteur de recherche à un assistant virtuel, il faut prendre conscience de la place que prend aujourd’hui la question de l’intention de l’internaute dans le fonctionnement du moteur.
Ce n’est peut-être pas très visible, mais c’est aujourd’hui un élément clé qui détermine les résultats que Google choisit de montrer à l’internaute.
Pour chaque requête, Google associe un type d’intention :
- Requêtes informationnelles pour lesquelles Google privilégiera les articles, billets, contenus encyclopédiques, tutoriels, etc. ;
- Requêtes décisionnelles/commerciales où Google redirigera vers des comparatifs, avis de consommateurs, tests, etc. ;
- Requête transactionnelle qui privilégiera les sites de e-commerce ;
- Les requêtes navigationnelles qui mèneront vers les pages d’accueil de sites, annuaires, sites de curation, etc. ;
- Les requêtes locales qui feront ressortir des résultats issus de Google My Business, Google Maps, Pages jaunes, Store Locator, etc.
Sur ce sujet, on conseillera la lecture d’une présentation d’Olivier Andrieu sur Slideshare intitulée « Comment identifier l’intention de recherche détectée par Google sur une requête ? » datant d’octobre 2021.
Google indique que l’intention détectée par Google peut varier selon le moment. Par exemple, effectuer une recherche sur les sapins de Noël en hiver et en été ne produira pas les mêmes résultats. En hiver, Google s’attend à ce que vous cherchiez à acheter un sapin, alors qu’en été ce ne sera pas la même finalité.
À l’image d’un humain, Google commence par essayer de comprendre la finalité de la question de l’utilisateur avant même de s’intéresser au sujet de la question. Et s’il ne perçoit pas correctement l’intention de recherche, la sélection de résultats proposée n’a aucune chance de convenir à l’internaute.
Des algorithmes de plus en plus humains ?
Il est d’ailleurs intéressant de constater que les noms donnés aux algorithmes de Google sont passés de noms d’animaux (donc en principe moins avancés intellectuellement que l’homme) à des noms faisant référence à l’être humain comme si ces algorithmes gagnaient progressivement en intelligence. Les deux derniers algorithmes de Google BERT et MUM ne sont, selon Google, que des acronymes, mais on ne peut s’empêcher d’y voir une patte humaine : Bert est un prénom masculin (diminutif d’Albert) et Mum signifie « maman » en anglais. Et d’après Google, MUM va permettre à Google d’être multitâche et d’avoir une forte capacité d’écoute et de compréhension…
L’algorithme le plus abouti de Google dans quelques années s’appellera-t-il L.I.B.R.A.R.I.A.N ? Seul l’avenir nous le dira…
Google, un assistant qui sélectionne l’information
Derrière la barre de recherche de Google, il y a donc des technologies et algorithmes de plus en plus complexes même si ce que perçoit l’internaute paraît de plus en plus simple et intuitif.
Derrière cette apparente facilité à rechercher de l’information, Google prend en fait de plus en plus la main sur la recherche elle-même, mais aussi les contenus sous couvert de vouloir aider l’internaute.
Google sait mieux que l’internaute ce qu’il recherche, il sait aussi mieux que le créateur du site ce qu’il a voulu dire et pour cela il n’hésite plus à réécrire les titres des pages qu’il affiche dans ses résultats ainsi que les méta descriptions. Et il n’y a pas grand-chose à faire pour aller contre cela.
Bref, Google se présente comme un assistant, mais il écoute finalement assez peu les consignes et n’en fait qu’à sa tête.
Le professionnel de l’information n’a d’autre choix que de composer avec un outil en perpétuel mouvement dont l’arrière-boutique se complexifie de jour en jour. Quelle est aujourd’hui l’expérience de recherche accessible au professionnel et que peut-il tirer des multiples nouveautés et évolutions ? C’est ce que nous allons voir dans les articles de ce même numéro « Comment utiliser Google pour des questions complexes ? Restez simple! »