
Dans une phase préliminaire de veille de manière générale et dans le cadre de cet article, nous recommandons d’utiliser un corpus de références d’articles de presse comprenant uniquement les titres, les sources et les premières lignes des articles.
Il existe différents moyens de récupérer un corpus de presse :
-
- Trouver un dataset/corpus d’articles mis à disposition librement sur le Web sur le thème qui nous intéresse. Cela existe, mais il reste tout de même rare de trouver précisément ce dont on a besoin ;
- Utiliser un agrégateur de presse professionnel comme Factiva, Newsdesk, Europresse ou Tagaday pour effectuer une recherche sur le thème qui nous intéresse et extraire un corpus conséquent de références d’articles ;
- Utiliser une plateforme de veille pour récupérer un corpus presse/actualités
- Récupérer soi-même un corpus d’articles depuis différentes sources comme Google Actualités, des sites de presse, etc., mais le processus est long et fastidieux et il est pratiquement impossible de récupérer un très gros volume de documents, car cela nécessite une importante intervention humaine.
Voir notre article « Quelles fonctionnalités de dataviz dans les plateformes de veille ? », Netsources N° 161 - novembre/décembre 2022
Trouver un dataset
C’est la solution la plus simple, mais qui fonctionne finalement le moins souvent.
On pourra interroger des moteurs de datasets comme :
-
- Google Dataset Search ;
- Kaggle ;
- Data World ;
- Les plateformes Open Data nationales et locales comme Data.gouv.fr par exemple ;
- Les moteurs académiques comme Dimensions, Lens, etc. si on s’intéresse à l’IST (ce qui n’est pas le cas ici) ;
- GitHub où certaines personnes partagent parfois des datasets.
Dans notre cas, on ne trouve pas de corpus d’articles de presse traitant de ChatGPT sur les sites susceptibles d’héberger des datasets. Une requête sur Google à la recherche de datasets sur le sujet ne nous permet pas non plus d’identifier de corpus d’articles clé en main.
On notera qu’on trouve sur Kaggle et Google Dataset Search des jeux de données proposés par des internautes regroupant un gros ensemble de tweets utilisant le hashtag #ChatGPT. C’est intéressant en soi même si cela ne répond pas à notre besoin dans le cadre de cet article.
Se créer un corpus à partir d’outils gratuits
Deuxième possibilité, gratuite certes, mais pas des plus simples ni des plus satisfaisantes. Se constituer soi-même un corpus en scrapant les résultats de moteurs d’actualités et en ajoutant soi-même des articles repérés après des recherches.
On peut ainsi récupérer un corpus d’articles sur Google Actualités avec la méthode suivante :
- Il faut tout d’abord récupérer un flux RSS sur le(s) mot-clé(s) de son choix. La manipulation se fait en deux temps en allant sur Google News puis en entrant notre requête. Ensuite, pour transformer sa recherche en flux RSS, il faut modifier l’URL en ajoutant
/rss/après la mention « .com ».
Pour notre exemple, on transformera l’URL suivante : https://news.google.com/search?q=delta%20»ChatGPT»&hl=fr&gl=FR&ceid=FR%3Afr en : https://news.google.com/rss/search?q=delta%20»ChatGPT»&hl=fr&gl=FR&ceid=FR%3Afr - Il faut ensuite se rendre sur Google Sheets pour extraire les articles du flux RSS. On utilisera alors la fonction IMPORTFEED qui consiste à entrer la formule suivante dans la première case du tableur : =IMPORTFEED(
"URL du flux RSS";"items"; VRAI ;250) - On peut ensuite ajouter d’autres groupes d’articles émanant d’un flux RSS (flux RSS d’une revue ou d’un magazine par exemple) toujours en utilisant cette fonction Importfeed.
- Enfin, on pourra rajouter manuellement des contenus issus de sites de presse, de recherche dans son lecteur RSS, etc., mais c’est manuel donc chronophage et inadapté pour de gros volumes.
- Il faut tout d’abord récupérer un flux RSS sur le(s) mot-clé(s) de son choix. La manipulation se fait en deux temps en allant sur Google News puis en entrant notre requête. Ensuite, pour transformer sa recherche en flux RSS, il faut modifier l’URL en ajoutant
Problème avec cette méthode : on peut enrichir son fichier dans Google Sheets au fur et à mesure en collectant des données dans le temps, mais quand on débute sur un sujet, on a peu d’articles (Importfeed impose une limite de 250 éléments maximum et dans la réalité on en a même souvent moins).
Dans le cas de notre exemple, cette fonction va nous permettre d’extraire à peine une centaine d’articles parlant de ChatGPT depuis Google Actualités là où les agrégateurs professionnels payants peuvent nous en retrouver des milliers avec le même mot-clé.
Tirer parti des plateformes de veille
Quand on dispose d’une plateforme de veille, il existe souvent un moyen d’interroger le corpus pour voir ce qui a été publié avant la mise en place de sa veille et il y a notamment des filtres pour ne visualiser que ce qui provient de la presse et des médias en ligne. L’antériorité est cependant parfois limitée. On pourra donc tester cette option au début de la mise en place d’une veille pour déterminer les angles et le champ sémantique.
Nous ne rentrerons pas plus en détail dans ce que les plateformes de veille ont à offrir, car nous avons détaillé cet aspect-là dans l’article « Quelles fonctionnalités de dataviz dans les plateformes de veille ? », Netsources N° 161 - novembre/décembre 2022.
Se créer un corpus à partir des agrégateurs de presse professionnels
La meilleure solution est de passer par un agrégateur de presse professionnel (tels que Factiva, LexisNexis Newsdesk, Tagaday ou encore Europresse), mais cela suppose d’avoir un abonnement auprès d’un ou plusieurs d’entre eux.
On entre sa recherche dans l’agrégateur puis on dispose généralement d’une fonctionnalité d’export pour extraire le corpus (titre, sources et premières lignes des articles citant les mots-clés de la requête) dans un format CSV, XLS, et RIS notamment.
Seul problème, il y a pratiquement toujours une limite dans le nombre de documents/références que l’on peut récupérer par export. Par exemple, sur l’agrégateur Lexis Nexis Newsdesk, la limite est de 5 000 références par export, sur Europresse de 1 000 et sur Factiva de 100 seulement.
Cela oblige donc l’utilisateur à relancer plusieurs mêmes requêtes sur des périodes différentes et à multiplier les exports et éventuellement ensuite à fusionner les différents fichiers récupérés dans Excel par exemple (Excel a une limite à 1 999 999 997 cases, ce qui laisse la possibilité d’avoir de très gros corpus).
Dans le cas de notre exemple, nous nous contentons tout d’abord de lancer une requête simple sur le terme
ChatGPTen limitant notre recherche à des contenus en français ou en anglais. Sur Factiva, cela génère 23 000 résultats et sur Newsdesk plus de 37 000
En passant en revue les premiers résultats, on se rend vite compte que cette requête génère un bruit important avec des articles qui ne mentionnent ChatGPT que de façon anecdotique dans l’article sans que ce ne soit véritablement le sujet de l’article ou des articles qui citent d’autres articles parus dans le même journal traitant de ChatGPT. Pour obtenir un corpus plus centré sur le thème qui nous intéresse, nous choisissons finalement de rechercher le terme ChatGPT dans le titre et les premières lignes de l’article.
-
- Sur Factiva, il existe un opérateur HLP=ChatGPT qui permet de rechercher sur le titre, la section et le « lead paragraph ». Sur Newsdesk, il existe un champ où il est possible de rechercher un terme dans les x premiers mots de l’article (par défaut, il s’agit des 100 premiers mots, mais ce champ est personnalisable). Les deux fonctionnalités sont donc proches même si elles limitent la recherche à des champs légèrement différents. On réduit donc à 10 000 articles sur Factiva et 23 000 sur Newsdesk, ce qui reste un volume trop important pour être analysé humainement.
Nous choisissons ensuite d’exporter les références des documents depuis Newsdesk, car il nous permet de ne pas trop multiplier le nombre d’exports.
-
- Sur Newsdesk, l’option « Télécharger/Exporter » puis « Données d’articles (Excel) » nous permet de récupérer un fichier avec les titres et les extraits d’articles (ainsi que de nombreuses autres métadonnées si nous le souhaitons). Sur Factiva, c’est beaucoup moins pratique, car il n’existe aucun export possible en Excel, mais uniquement en RTF, c’est-à-dire au format texte ce qui n’est absolument pas comparable. Il y a donc derrière un gros travail de reformatage, car la plupart des outils d’analyse ont besoin de données dans des formats tableurs comme XLS, CSV, mais pas Word ou RTF et il y a un temps de travail important consacré à l’export des données.
Nous effectuons donc cinq exports sur Newsdesk pour récupérer les données des 23 000 références d’articles dans un fichier Excel.
Nous y parvenons mais force est de constater que récupérer un corpus de presse à analyser n’a pas été aussi simple ni aussi rapide qu’on pourrait le penser. Maintenant il va falloir s’adapter aux outils que l’on va pouvoir utiliser, au temps que l’on est capable d’allouer ainsi qu’au budget.
Les fonctionnalités intégrées aux agrégateurs de presse : un premier niveau d’information
Comme nous avons pu le voir, récupérer un corpus de presse est une étape à part entière qu’il faut réaliser avec sérieux et minutie. Quand on dispose d’un agrégateur de presse professionnel, il pourrait être intéressant de se limiter aux fonctionnalités d’analyse fournies par l’agrégateur et qui permettent d’éviter d’avoir à télécharger un corpus.
Nous avions écrit un article en 2018 sur les fonctionnalités d’analyse offertes par les agrégateurs de presse professionnels intitulé « Dataviz : les agrégateurs de presse font-ils la bonne analyse ? », Bases N° 357 - mars 2018.
On constate que les fonctionnalités n’ont que peu évolué depuis l’écriture de cet article et on pourra donc s’y référer pour en savoir plus.
Dans le cas de notre sujet, nous avons testé les fonctionnalités d’analyse proposées par Factiva et LexisNexis Newsdesk.
-
- Pour LexisNexis Newsdesk, cela nous permet de visualiser différents graphes comme la couverture au fil du temps, la couverture médiatique par journaliste, par source, les entités nommées (personnes, entreprises, produits, etc.), les lieux cités et les sources, les types de sources, les sujets, secteurs d’activité et thèmes, etc.
Ces graphiques offrent un premier niveau d’analyse, mais on est vite limité. D’une part, cette analyse ne s’applique qu’au corpus de Newsdesk et il est impossible d’y inclure des données externes. D’autre part, les graphes proposés ne permettent pas de rentrer dans les détails des données pour l’analyse textuelle (celles qui nous intéressent ici pour découvrir les thèmes et le champ lexical). On visualise seulement une dizaine de mots-clés par nuage de mots-clés, ce qui ne permet qu’une analyse de premier niveau.
-
- Le constat est le même sur Factiva.
Ces solutions d’analyse intégrées présentent quand même un avantage : quand on clique sur les termes des nuages de mots-clés, on peut visualiser directement les articles associés à ces mots-clés, ce qui est intéressant pour naviguer dans le corpus et visualiser d’un clic les articles associés à un terme.
Malheureusement, ces fonctionnalités ne vont pas être suffisantes pour déterminer les angles de sa veille et le champ sémantique même si cela peut apporter quelques pistes intéressantes. Il va donc falloir partir à la recherche d’outils pour analyser les corpus d’articles que nous avons récupérés au format XLS.
Deuxième partie : l’analyse des articles de presse
Dans le cas qui nous occupe, il s’agit de faire de l’analyse textuelle pour repérer les thèmes et les mots-clés les plus utilisés. On entre alors dans le champ de la bibliométrie et du text mining et la représentation visuelle la plus adaptée est le nuage de mots-clés.
Nous avons testé plusieurs outils pour nous aider dans cette démarche.
Les outils de nuages de mots-clés : simples, mais inadaptés pour de gros volumes
Pour commencer, nous avons décidé de tester des outils simples et gratuits qui permettent de générer des nuages de mots-clés à partir de contenus textuels comme TagCrowd par exemple.
Le principe est simple, on copie-colle un texte ou on charge un fichier et l’outil nous génère un nuage de mots-clés les plus utilisés.
Dans notre cas, le résultat est absolument catastrophique avec un nuage de mots-clés ressemblant plus à des onomatopées qu’à de véritables mots.
Ces outils seront donc à oublier dans un contexte d’analyse d’un gros volume de données. Nous nous sommes donc tournés vers des outils plus perfectionnés.
Les outils de text mining et analyse bibliométrique : Voyant Tools et CorText
Bonne nouvelle, il existe plusieurs outils de text mining et d’analyse bibliométrique gratuits. Ces outils sont développés par des universitaires ou organismes publics qui en ont besoin dans le cadre de leur métier et les mettent gratuitement à disposition.
Deux d’entre eux ont particulièrement retenu notre attention : Voyant Tools et CorText.
1 - Voyant Tools
Dans cette catégorie, nous avons tout d’abord testé Voyant Tools qui présente l’avantage d’être très simple à prendre en main (Cf. Figure 1. Interface de Voyant Tools). Il suffit de charger le document comportant les références d’articles puis l’outil effectue ensuite l’analyse.
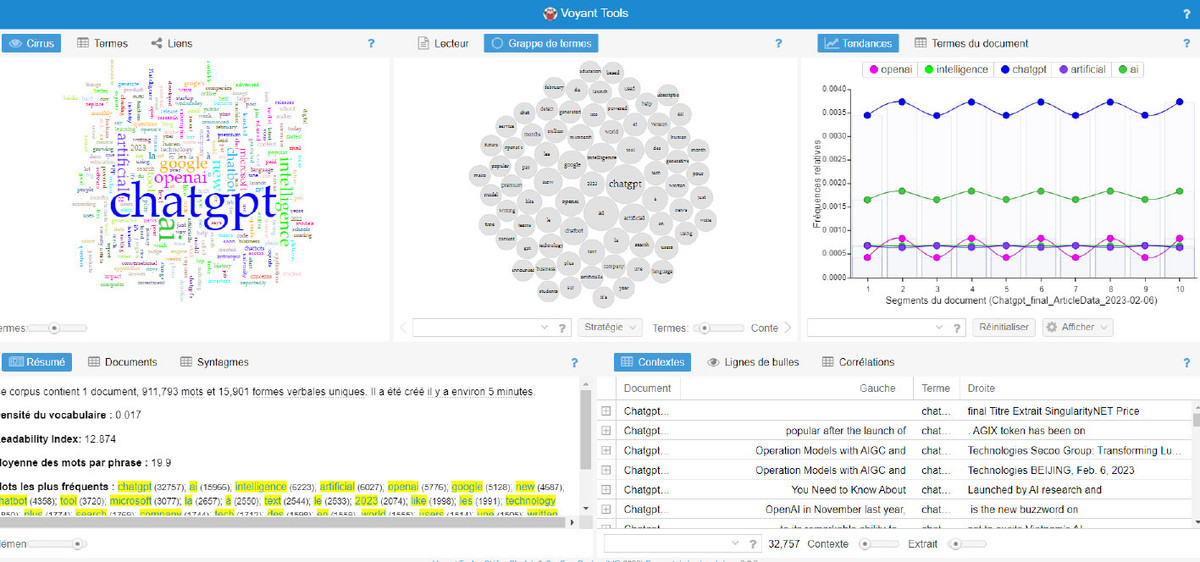
Figure 1. Interface de Voyant tools
En termes de dataviz, l’outil permet de visualiser dans le nuage de mots-clés ou la représentation sous la forme de grappe de termes, jusqu’à 500 mots-clés les plus cités dans le corpus. En dehors de l’aspect purement dataviz, on peut également visualiser l’ensemble des termes extraits du corpus classés par nombre d’occurrences dans un tableau (dans notre cas, il y avait plus de 15 000 termes).
Le fait de pouvoir aller au-delà de la dizaine de mots-clés (ce qui représente la limite des fonctionnalités intégrées aux agrégateurs de presse) permet de mieux voir les angles associés à ChatGPT comme la question de l’évolution des moteurs et de l’impact sur la recherche d’information, les enjeux de ChatGPT dans le monde de l’éducation, la question du modèle économique de ChatGPT, les différents domaines et métiers où ChatGPT pourrait changer les choses, la question de l’intelligence ou non de l’IA, les menaces potentielles.
On repère également toute une liste de mots-clés allant de termes définissant ChatGPT comme IA conversationnelle, chatbots, IA générative à des noms de personnes qui s’expriment sur la question, des sociétés et entreprises citées, etc.
2- CorTexT (Tx2) : très puissant, mais plus complexe à prendre en main
Nous avons ensuite testé (https://www.cortext.net/) + CorTexT (Tx2).
Pour apprendre à utiliser CorTexT (Tx2) sur des problématiques adaptées aux professionnels de l’information, on signalera les tutoriels vidéo réalisés par Mathieu Andro qui sont très bien faits.
- Pour utiliser CorTexT (Tx2), il faut tout d’abord se créer un compte.
- Ensuite, il faut charger notre corpus et pour ce faire, il faut impérativement le mettre au format Zip.
- Pour l’intégrer à l’outil, on se rend sur le Dashboard puis on clique sur « Upload File » puis sur « Corpus », on charge alors le fichier .zip et on lance l’ajout. Si tout a fonctionné correctement, on a un drapeau vert.
- On peut ensuite créer différentes sortes d’analyses textuelles. On cliquera sur « Start Script » puis on choisira le type d’analyse qu’on souhaite lancer.
Plusieurs analyses et représentations nous ont été utiles. Voici quelques éléments de méthode pour apprendre à les utiliser.
Extraction de termes et expressions d’un corpus
La première analyse utile par rapport à notre exemple est celle intitulée « Terms Extraction ».
Elle permet de récupérer les termes et expressions les plus cités dans notre corpus. Avantage par rapport à Voyant Tools : on va au-delà du simple mot-clé et on peut visualiser des expressions et morceaux de phrases, ce qui permet de mieux mettre les termes en contexte.
C’est intéressant, mais, à ce niveau, on n’est pas réellement dans de la dataviz, car l’analyse est uniquement constituée d’un tableau.
Extraction d’entité nommée et graphes relationnels
Pour réaliser une analyse visuelle de notre corpus, il va falloir utiliser d’autres fonctionnalités de CorTexT (Tx2). Et cela se fait en deux étapes.
La première consiste à extraire automatiquement les entités nommées (nom de personnes, lieux, entreprises, etc.) de son corpus textuel.
-
- Pour cela, on choisira le script « Named entity Recognizer » que l’on ira appliquer au corpus que nous avions chargé sur l’outil précédemment;
- On sélectionnera ensuite quelles entités nommées on souhaite extraire parmi celles disponibles : on a ainsi le choix entre des entités nommées date, événements, langue, lieux, produits, personnes, etc.;
- Puis on choisit la langue du contenu sur laquelle on travaille, le nombre de fois minimum où une entité doit apparaître pour être prise en compte (le minimum étant 1) et le nombre d’entités maximum que l’on doit extraire.
On récupère alors des listes d’entités nommées au format tableau (une par thème choisi donc une pour les lieux, une pour les personnes, une pour les produits, etc.).
On notera tout de même que si cette fonctionnalité est très intéressante, tout n’est pas parfaitement exact et fiable. L’outil considère visiblement que Valentine’s Day, Gmail, Salut ChatGPT ou encore « rien comprendre » sont des personnes…
Dans un second temps, on peut créer des graphes relationnels à partir des entités nommées extraites pour visualiser les liens entre les différents éléments. On choisira alors le script « Network mapping » puis on sélectionnera sur quelles entités nommées on souhaite travailler (personnes, produits, organisations, etc.) - Cf. Figure 2. Graphe relationnel à partir des entités nommées « Organisations/Entreprises ».
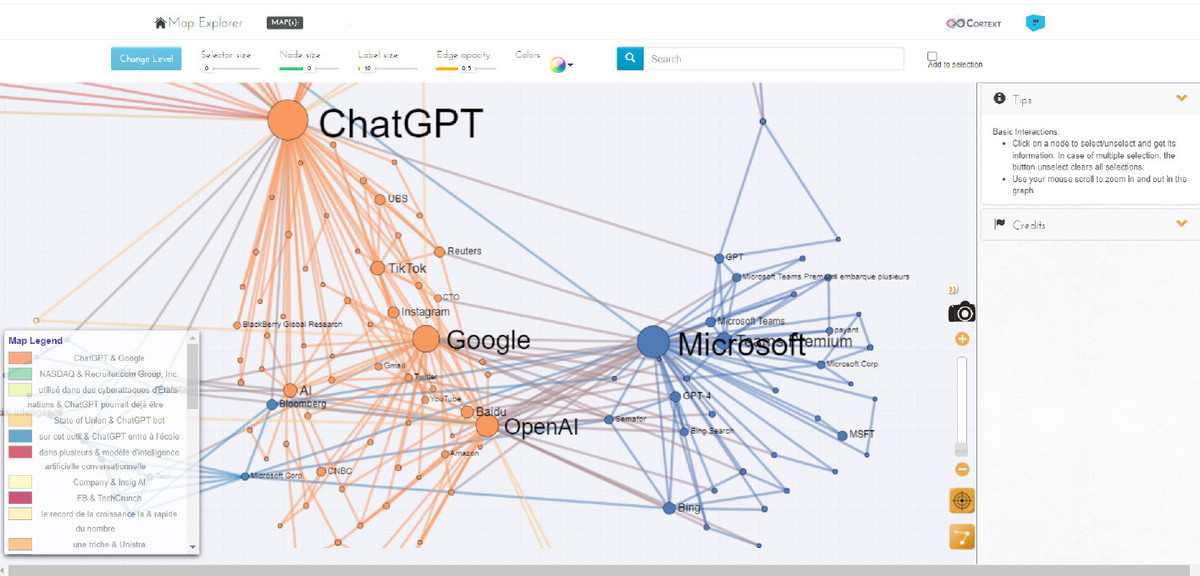
Figure 2. Graphe relationnel à partir des entités nommées « Organisations/Entreprises ».
Cette représentation visuelle est intéressante, car elle permet d’identifier les organisations les plus citées, mais aussi les liens entre les organisations citées ainsi que des regroupements thématiques (un bloc autour de ChatGPT, un bloc autour de Microsoft, un autre autour de Google, etc.).
Cela nous a par exemple permis de repérer quelques entreprises impliquées dans l’IA conversationnelle, mais avec une visibilité moindre que ChatGPT, Microsoft et autres géants, et que nous n’avions pas repérées humainement. À l’inverse, la dataviz a aussi créé des liens entre des organisations qui n’avaient pas lieu d’être et qui peuvent ainsi conduire à des contresens. Il y avait par exemple des entreprises citées les unes à côté des autres dans plusieurs article, ce que la dataviz a traduit par des liens entre ces différentes sociétés. Mais quand on regarde les articles eux-mêmes, on se rend compte qu’il s’agissait d’articles annonçant les sommaires d’études de marché et qui citaient en premières lignes les différentes entreprises mentionnées dans l’étude les unes à la suite des autres. Et cela reste quelque chose de difficile à vérifier, car l’outil de dataviz ne nous permet pas de cliquer sur les entités nommées et de voir les articles associés dans notre corpus s’afficher.
La dataviz en amont de la veille : complémentaire à l’humain, mais pas miraculeux
Au final, cet exercice a été riche en enseignements :
-
- L’usage de la dataviz en amont de la veille nous a permis d’identifier des thèmes et des mots-clés que nous n’avions pas repérés en passant en revue manuellement des résultats de moteurs, d’agrégateurs de presse ou de bases de données.
- À l’inverse, il y a des éléments très pertinents que nous avons pu repérer humainement à côté desquels la représentation visuelle est complètement passée à côté. Il s’agit donc de deux démarches complémentaires.
- L’autre enseignement clé est l’importance d’avoir un bon corpus pertinent et représentatif. On peut vite se retrouver à faire dire n’importe quoi aux données.
Dans le cas de notre exemple, nous avons par exemple été surpris de ne pas voir apparaître certains acteurs et organisations sur le thème de ChatGPT tels que certains moteurs de recherche moins « mainstream » comme Neeva, DuckDuckGo, etc. qui s’expriment pourtant sur le sujet. Après vérification, il s’avère que le problème ne vient pas de la dataviz qui n’aurait pas réussi à faire remonter ces organisations, mais bien du corpus qui ne contenait aucun article mentionnant ces acteurs.
D’où l’intérêt de ne pas construire sa veille uniquement à partir d’un seul typede données, aussi important soit-il (comme ici la presse), et de bien diversifier ses sources d’informations (réseaux sociaux, sites institutionnels, etc.).