

La start-up a été créée en 2018 par Freddy Mini, ex-CEO de Netvibes, que nous avons interviewé.
D’où vous est venue l’idée de TrustedOut ?
Freddy MINI
Le nom : TrustedOut vient de “if it’s not Trusted In, it can not be Trusted Out” (si vous n’avez pas confiance dans ce qui entre, vous ne pouvez pas avoir confiance dans ce qui sort). Les Américains disent “Garbage in, garbage out”.
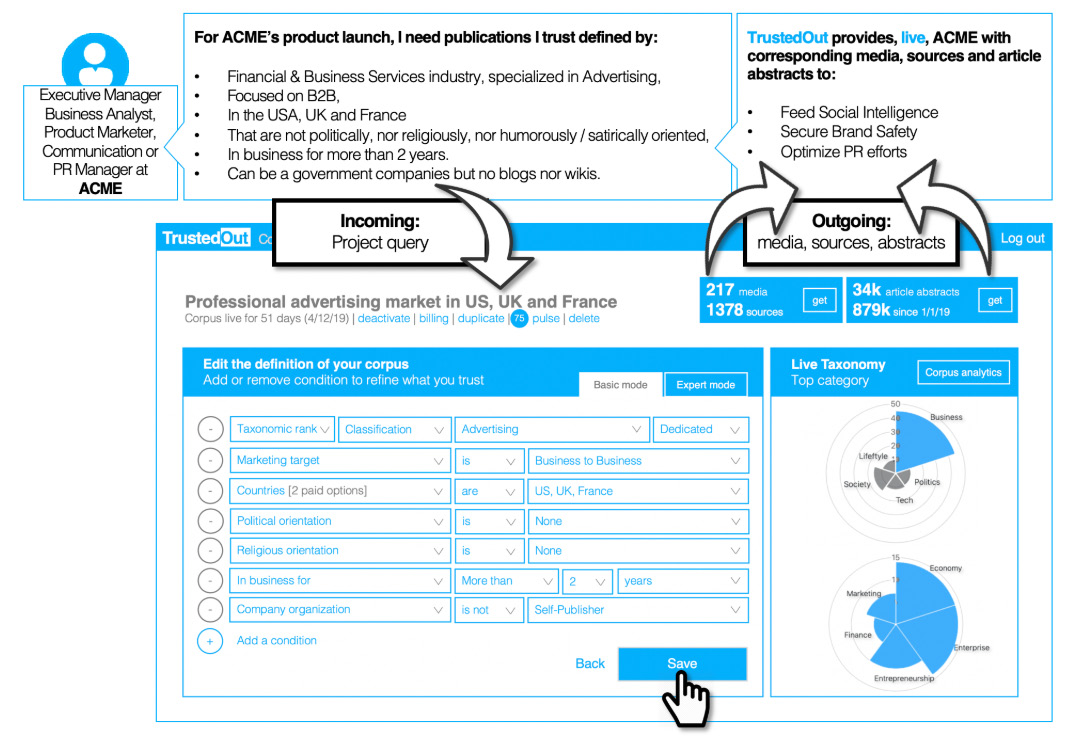
Figure 1. Interface de TrustedOut
Notre vision : la perte de confiance, actuelle et brutale, dans l’intégrité de l’information a des conséquences directes sur l’éducation, les opinions et, plus important encore, la prise de décision. Comme nous pensons que le vrai et le faux sont subjectifs et souvent, personnels, le fact-checking magique ne redonnera pas une confiance universelle. Le profiling des auteurs est également illusoire (en plus d’être perturbant) car les auteurs ont plusieurs (ou aucune) identité, qu’ils ne sont pas experts en tout et que leur expertise est temporaire et là encore subjective.
La seule, et la bonne solution, est donc de profiler le publisher (éditeur), et en particulier les valeurs de son logo, de sa marque. Car le logo est l’épine dorsale, l’élément vital et donc il protège, défend à tout prix le Publisher. En profilant les valeurs du Publisher, vous pouvez définir votre confiance en lui.
Et comme la confiance est personnelle (personne ne peut vous forcer à avoir confiance en quelque chose), il fallait fournir une base de données des profils des sources d’information pour que les analystes, professionnels du marketing, PR Managers puissent définir leurs corpus d’information (l’ensemble du contenu qui sera utilisé).
Alors qu’il y a un fort intérêt pour les algorithmes d’intelligence sémantique (BI) et la programmatique publicitaire, rien n’existait dans l’intelligence des corpus. D’où notre slogan : Corpus Intelligence.
Pourriez-vous nous expliquer en quelques lignes le fonctionnement de l’outil et quelle pourrait être son utilité pour des professionnels de l’information ?
Vous créez un corpus par une requête en ajoutant des conditions (pays, taxonomie, typologie des sources, etc.) - (voir figure 1),
TrustedOut vous montre à chaque étape le nombre de media, sources, nombre d’articles par jour en moyenne et nombre d’abstracts que nous avons en archive pour cette requête. Une fois satisfait, vous pouvez soit télécharger ces media et sources ou connecter votre système pour que TrustedOut l’alimente automatiquement et en permanence.
Sur votre site, vous définissez TrustedOut comme une « media database ». Qu’est-ce que le terme media englobe exactement? Et de quelles informations précises dispose-t-on pour chaque média ?
Nous couvrons, pour l’instant, tout ce qui a un statut de Publisher, donc news, magazines, revues… quelle que soit la configuration technique du Publisher.
Rien ne nous empêche de profiler des sources payantes ou autres. Il nous faut simplement un accès aux sources pour les classifier.
Les informations par source sont à la fois intangibles (data collection: nom, propriétaire, CA, traffic…) et tangibles (content classification: taxonomie, perçu comme toxique (fake news, junk science…). En tout plus de 60 champs et 400 catégories.
L’outil se focalise pour l’instant sur les US et la France. D’autres pays vont-ils être ajoutés prochainement et si oui, dans quel délai ?
UK, Espagne, Mexique, Portugal, Brésil et aussi Canada francophone et anglophone d’ici la fin de l’année
Vous disposez déjà d’un partenariat avec Digimind. Avez-vous d’autres partenariats avec d’autres plateformes de veille ? TrustedOut est-il également proposé comme un outil à part sans lien avec des plateformes ?
Nous travaillons actuellement à des partenariats avec les agences publicitaires et trading desks pour leur fournir des listes blanches qui résolvent le problème aigu de la Brand Safety.
TrustedOut sera également ouvert en libre-service en novembre avec un tarif mensuel de 500 euros pour 1 corpus et 300 euros pour chaque autre corpus.
Storyzy : du fact-checking à l’évaluation des sources, il n’y a qu’un pas
Storyzy catalogue les sites et vidéos de désinformation. Nous sommes allés interviewer Pierre Albert Ruquier, Directeur Marketing et co-fondateur de Storyzy
Comment est né Storyzy et comment a-t-il évolué depuis son lancement ?
Pierre Albert RUQUIER
A l’origine Storyzy s’appelait Trooclick, fondé par des professionnels de l’information et entrepreneurs. J’ai par exemple été journaliste durant 25 ans (presse écrite, BFMBusiness, co-fondateur de 6médias digital, France-Soir, Sipa News). Avec Trooclick nous avons, grâce au traitement automatique des langues et au machine learning, commencé à automatiser la vérification des informations (fact-checking). Nous avons même sorti un add-on qui s’appelait Glitch Spotter et qui donnait le taux de fiabilité d’un article donné dans le domaine des informations économiques.
Les raisons pour lesquelles nous avons abandonné cette piste sont multiples : trop complexe techniquement d’étendre le système à d’autres thématiques que le business, pas de possibilité de développer un add-on sur les mobiles, un modèle économique difficile (personne prêt à payer et volumes insuffisants pour monétiser par la publicité), peu d’erreurs factuelles dans les articles sur l’économie.
A partir de ce constat nous avons décidé d’utiliser notre techno dans un premier temps pour extraire les discours directs et indirects des articles. Cela nous a permis de créer une énorme base de données de citations avec leurs auteurs. Nous avons mis en ligne avec le site Internet d’Euronews le premier moteur de recherche de citations (qui dit quoi sur quoi), mais nous avons dû arrêter après un peu plus d’un an car l’audience n’était pas suffisante. Nous avions aussi développé un moteur similaire avec le groupe Mondadori qui s’est également arrêté.
Ensuite nous avons commencé à adapter nos algorithmes pour classifier les sources sur Internet (sites, blogs et chaînes vidéo) en fonction de leur fiabilité. Cela nous permet d’alimenter une base de données de sources catégorisées (complotisme, intolérance, propagande, pseudoscience, piège à clic, satire).
Aujourd’hui notre activité consiste d’une part à vendre notre base de données à des annonceurs qui ne souhaitent pas que leurs campagnes publicitaires s’affichent sur des sites de cette nature, d’autre part à taguer des sources issues par exemple d’outils de veille comme Brandwatch ou d’agrégateurs comme Relaxnews et enfin de développer un moteur de recherche qui trie les résultats en fonction de la fiabilité des sources. Moteur de recherche baptisé Newscoach.
Figure 2. Interface de Newscoach
Pourriez-vous nous expliquer en quelques lignes le fonctionnement de Storyzy aujourd’hui et son utilité pour des professionnels de l’information?
Pour des professionnels de l’information, notamment dans le monde scolaire ou de l’enseignement supérieur, Newscoach est tout à fait adapté pour trier les résultats selon la fiabilité sur des sujets d’actualité. L’outil n’intègre pas de bases de connaissance mais il peut faire gagner du temps pour des recherches liées à l’actualité puisqu’il tague les sources en fonction de leur fiabilité. Dans un cadre éducatif pour montrer à un public d’élèves des exemples concrets par exemple sur la désinformation, le racisme...
Comment est composé le corpus de votre base de données ? Quels sont les critères pris en compte pour déterminer la fiabilité et la transparence d’une source ? Comment y effectue-t-on des recherches ?
Les critères qui nous ont permis à l’origine de constituer une première liste de sources annotées sont des critères journalistiques comme la règle des 5W, l’usage du conditionnel, la citation des sources, la transparence de l’éditeur... etc.
Un petit moteur de recherche aujourd’hui accessible gratuitement sur Newscoach via login et mot de passe et limité à 10 requêtes permet de se faire une idée de la recherche des contenus dans notre base de données. Nous travaillons en permanence à améliorer la pertinence des résultats retournés, qui n’est pas encore optimum (en tout cas loin des standards des gros moteurs de recherche tels que Google).
S’agit-il d’un service sur abonnement ? Est-il possible d’avoir quelques éléments tarifaires ?
Nous vendons l’accès illimité à Newscoach aux établissements scolaires et d’enseignement supérieur entre 1 et 2 euros par élève et par an.
Concernant la publicité nous vendons notre base de données actualisée en permanence 400€ par annonceur et par mois.
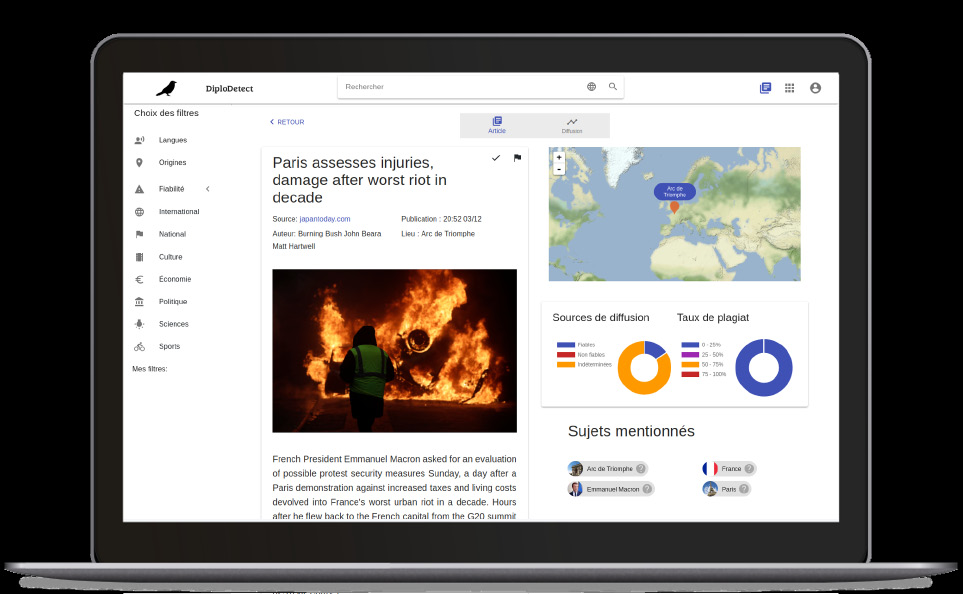
Figure 3. Interface de Neutral News
Neutral News : un «Google news made in France» qui évalue la qualité des sources et des contenus
Neutral News a été créé par Arnaud Henric, Jonas Bouaziz et Jérémie Zimmer, trois étudiants de l’EPITA (école d’ingénierie informatique). L’application Neutral News centralise et analyse en temps réel les flux d’articles publiés par plusieurs milliers de sources numériques afin de contextualiser l’information et d’apprécier son degré de fiabilité.
D’où vous est venue l’idée de Neutral News ?
Jonas BOUAZIZ
Nous avons commencé à développer Neutral News pour un projet scolaire dont le sujet était libre. L’idée de départ était de pouvoir contextualiser un article en proposant d’autres articles relayant le même événement. Nous voulions alors mettre en avant l’importance du biais géographique et temporel dans la rédaction d’un sujet. Au fur et à mesure de nos discussions avec des professionnels de la presse, nous nous sommes rendu compte que la validation croisée que permettait l’agrégation d’articles leur était très utile pour vérifier une information avant de la diffuser. Ensuite face aux demandes, nous avons décidé d’automatiser ce processus de vérification.
Pourriez-vous nous expliquer en quelques lignes le fonctionnement de l’outil et quelle pourrait être son utilité pour des professionnels de l’information ?
En nous basant sur une liste de 7000 sources de presses du monde entier, nous mettons en corrélation les articles (sans distinction de langues) pour les regrouper sous forme d’événements. Cela nous permet de proposer une revue de presse aussi bien internationale que nationale. Chaque article est récolté en temps réel pour retracer la diffusion mondiale d’une information et avoir un indice de fiabilité basé sur divers critères tels que le type et les relais de propagation, le style d’écriture ou bien la subjectivité du texte. Il est maintenant possible de retrouver les tweets faisant référence à un événement pour en analyser plus précisément l’impact.
L’utilisation de Neutral News peut donc fortement varier en fonction des besoins. Certains vont se concentrer sur la surveillance en temps réel d’un événement, d’autres seront plus intéressés par la détection d’informations manipulées ou la vérification d’information.
Par exemple, l’un de nos utilisateurs, journaliste, utilise cet outil pour vérifier rapidement la fiabilité d’une information et pour varier les sources d’information afin de ne plus se baser principalement sur les dépêches de l’AFP et ainsi rédiger des articles plus originaux et complets.
Combien de sources sont indexées dans votre corpus ? S’agit-il uniquement de médias presse ou plus largement toute source susceptible de publier des actualités ?
Nous indexons actuellement environ 7000 sources. Bien que ce nombre évolue vite, nous laissons à l’utilisateur la possibilité d’ajouter ses propres sources en insérant simplement les noms de domaine dans l’interface dédiée. Pour le moment nous avons principalement référencé des médias de presse, mais nous pouvons tout aussi bien référencer des blogs ou autre type de sources. Nous récupérons la même quantité d’informations d’une source qu’un utilisateur lambda. Par exemple sur lemonde.fr nous récupérons la totalité des articles gratuits, mais seulement le début des articles payants. Nous travaillons la possibilité de laisser l’utilisateur inscrire ses identifiants pour accéder à une source afin qu’elle puisse être analysée dans son intégralité.
Quels sont les critères pris en compte pour déterminer la fiabilité et la transparence d’une source ?
Seuls les journalistes travaillant sur Neutral News sont habilités à déterminer la fiabilité d’une source selon leurs appréciations personnelles. Nous pensons que seuls les professionnels de la presse ont autorité pour juger de la fiabilité d’une source d’informations. Bien entendu cela induit donc un biais de valeur dans nos algorithmes de détection d’informations manipulées, car la fiabilité des sources de diffusion fait parties des critères pris en compte. C’est pour cela que nous laissons la possibilité à l’utilisateur de personnaliser la fiabilité des sources d’informations selon ses propres jugements afin que l’algorithme de détection s’adapte à chaque utilisateur.
Quelles sont les fonctionnalités de recherche proposées par votre moteur de recherche ?
Le moteur de recherche de Neutral News permet de faire des recherches sans se préoccuper de la langue des résultats. Par exemple si nous voulons trouver des articles russes évoquant Emmanuel Macron, nous n’avons pas besoin de transcrire son nom en cyrillique. Nous proposons aussi divers filtres permettant d’affiner le résultat, notamment la tranche horaire, les langues, la fiabilité, les sources et leurs origines, les catégories ... En combinant les divers filtres et possibilités de recherches, nous pouvons accéder à des résultats très précis en quelques clics, ce qui aurait été très lourd et compliqué à obtenir sur un agrégateur d’actualité classique comme Google News.
Votre outil est-il déjà commercialisé ? Quels sont les modèles d’abonnement ? Et pouvez-vous nous fournir quelques éléments tarifaires ?
L’outil est actuellement en phase de bêta-testing chez nos principaux partenaires, notamment au sein du Ministère de l’Europe et des Affaires Étrangères. La grille tarifaire n’est pas encore établie mais sera variable selon l’utilisation et la taille des organisations.
Figure 2. Interface de Newscoach
Zoom sur quelques autres acteurs
Au-delà de ces trois outils très différents par leurs approches mais tous aussi prometteurs, on voit également se développer d’autres initiatives.
Parmi les plus visibles, on trouve des plugins qui s’intègrent à son navigateur et fournissent une note ou un code couleur pour évaluer le degré de fiabilité d’une source. Ces outils ne sont pas sans rappeler ce qui se passe dans un tout autre domaine avec les app comme Yuka, Foodvisor, Kwalito, ScanUp qui scannent notre alimentation et propose des scores nutritionnels.
L’un des plus connu s’appelle Newsguard. Il est d’ailleurs utilisé sur le navigateur de Microsoft Edge et vient tout juste d’être lancé en France. Il était déjà présent aux Etats-Unis, au Royaume-Uni, en Italie et en Allemagne.
Le principe est simple : l’outil attribue des notes de « crédibilité » et de « transparence » aux médias et sites d’actualités. Une fois le plugin installé, une icône de couleur (vert, orange, bleu, gris et rouge) apparaît à côté de chaque résultat lors d’une recherche sur un moteur ou bien dans la barre d’url lorsque l’on se trouve sur un site à condition bien sûr que le site soit évalué ou en cours d’évaluation par Newsguard. La société emploie 35 personnes dont 6 dédiées aux médias français sous la supervision d’Alice Antheaume, directrice exécutive de l’école de journalisme de Sciences-Po, essentiellement des journalistes chargés d’évaluer les médias et sites d’actualités.
Le principe n’est pas sans rappeler le Décodex du Monde, mais cette fois-ci l’outil n’est pas directement lié à un titre de presse. Néanmoins, l’outil est très critiqué depuis son lancement que ce soit par les sites mal notés que par des journalistes sérieux.
Dans la même veine, on trouve les extensions TrustedNews sur Chrome uniquement (qui appartient désormais à Factmata). Factmata propose également une API payante qui permet d’entrer l’url d’un article ou d’une page, qui en analyse le contenu afin de détecter d’éventuels biais, contenus offensants, etc. et évalue la page sur une échelle allant de « content may be harmful » à « content looks good ». On peut tester l’outil gratuitement en ligne mais il ne fonctionne que sur des contenus en anglais.
Sur un tout autre modèle, on trouve également la start-up Credder (voir figure 4) lancé à la fin de l’année 2018. Le but est ici d’évaluer la fiabilité des contenus, des sources et des auteurs. Cette évaluation est réalisée conjointement par des journalistes qualifiés et des internautes et chaque article, auteur ou média dispose alors d’un pourcentage de crédibilité. L’outil ne propose pas d’extension mais on peut y effectuer des recherches sur le titre d’un article, le nom d’un auteur ou le nom d’un média. L’outil ne semble proposer que des contenus et sources en anglais.
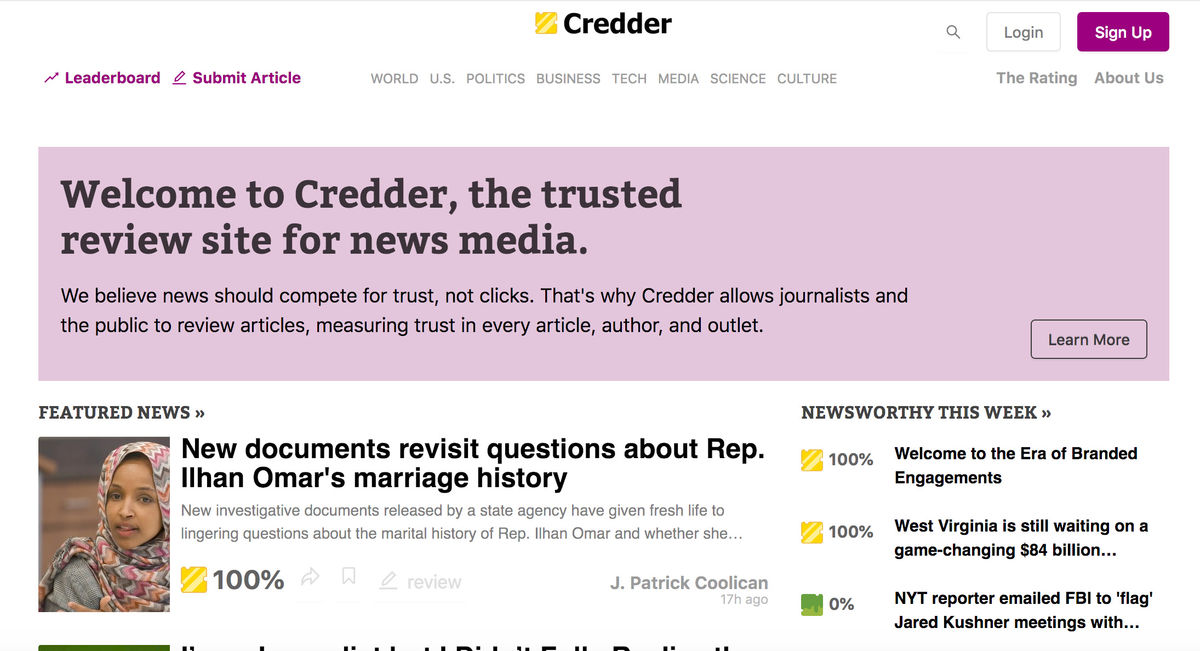
Figure 4. Credder
On citera également Nuzzel, que certains de nos lecteurs connaissent et utilisent, et qui a lancé son NuzzelRank qui note (sur 10) et classe les sites Web et médias par « autorité ». Si on peut visualiser le top du classement gratuitement, la recherche sur le moteur est en revanche limitée à la version payante de Nuzzel. Là encore, l’outil est très critiqué depuis son lancement.
L’évaluation des sources est effectivement un sujet sensible qui peut parfois déraper...
On citera ainsi l’annonce d’Elon Musk, le fondateur de Tesla, en mai 2018, qui disait vouloir créer un site d’évaluation des articles et des journalistes appelé Pravduh (en référence à la Pravda mais le nom de domaine était déjà pris). Cette annonce faisait suite à une série d’articles peu flatteurs sur Tesla qu’Elon Musk aurait peu appréciés... Depuis cette annonce, il ne semble pas avoir mis son projet à exécution...
Notre avis sur ces nouveaux outils
Si l’idée d’évaluer les sources grâce à des outils clé en main est intéressante sur le papier, on voit bien qu’il s’agit là d’un sujet complexe et sensible à la fois.
Car ces initiatives ne sont pas à l’abri d’être détournées. Il existe toujours un risque de conflit d’intérêt et toute évaluation humaine, s’accompagne de biais et d’une part de subjectivité.
Il ne faut donc pas prendre ces scores et évaluations pour argent comptant et continuer à faire marcher son esprit critique.
Cette nouvelle génération d’outils est néanmoins intéressante dans un contexte de veille et de recherche d’information car ces derniers permettent d’obtenir de premiers éléments sur les sources et parfois sur les contenus et les auteurs, de mettre en évidence des sources à regarder de plus près car potentiellement peu fiables et d’offrir une vision complémentaire à notre propre jugement humain.
On retrouve ici cette complémentarité entre l’humain et la machine.
Il ne faudra pas hésiter non plus à combiner et croiser plusieurs de ces outils afin d’obtenir différents points de vue.