Sélectionner le numéro de "Bases" à afficher
Lecteurs RSS : vers un nouveau souffle ?


Ne dites plus « lecteurs de flux RSS » mais « lecteurs d’information » ou « App d’actualité ». Nouvelles applis, nouvelles fonctionnalités, nouveaux looks, nouvelles promesses… Au cours de leur veille outils, les professionnels de l’info ont vu apparaître dernièrement de nouveaux acteurs, avec un discours marketing prometteur. Les lecteurs se moderniseraient-ils au point de gagner en notoriété ? Faut-il se préparer à remplacer Feedly ou Inoreader ? C’est à ces questions que nous nous proposons de répondre.
Apparues dans le sillage du déploiement de l’IA à grande échelle, ces plateformes sont de deux natures différentes. Il y a celles qui se présentent comme des « apps d’actualité », conçues pour être consultées principalement ou uniquement sur mobile, et celles qui se présentent davantage comme des lecteurs RSS consultables sur le web, même si leur fonctionnement est parfois différent.
Si leur défi d’apparaître (enfin!) comme une solution face à la « fatigue informationnelle » qui touche le grand public réussit, cela pourrait normaliser l’usage des lecteurs et créer le réflexe du grand public de centraliser son actualité pour mieux s’approprier l’information. Un rêve éveillé pour les veilleurs souvent seuls à s’émerveiller devant le potentiel d’un lecteur de flux RSS.
Et si les lecteurs RSS reviennent sur le devant de la scène auprès du grand public, cela entraînerait aussi des conséquences positives pour les professionnels car cela pourrait engendrer de nouveaux développements : des sites qui remettent du RSS, de nouveaux outils et nouvelles fonctionnalités, etc. En attendant, qu’ont-elles vraiment à offrir aux veilleurs, grands consommateurs d’information ?
Lire aussi :
Maîtriser le RSS, le socle inamovible de la veille (Netsources N° 159 - juil/août 2022)
Comment choisir la méthode la plus adaptée pour mettre une source en veille à partir d'un flux RSS ? (Netsources N° 159 - juil/août 2022)
Comment récupérer un flux RSS sur les moteurs web et Google Actualités ? (Netsources N° 159 - juil/août 2022)
Comment récupérer des flux RSS sur les réseaux sociaux ? (Netsources N° 159 - juil/août 2022)
Comment transformer une newsletter en flux RSS ? (Netsources N° 159 - juil/août 2022)
Comment récupérer un flux RSS sur la majorité des sites web ? (Netsources N° 159 - juil/août 2022)
Quel lecteur de flux RSS choisir en 2020 ? (Bases N° 384 - sept 2020)
Sur quoi se basent ces outils pour réenchanter l’information ? Mode de consultation épuré inspiré de celui des réseaux sociaux, ouverture des formats d’intégration des RSS aux APIs, fonctionnalités IA qui facilitent la consultation des corpus… voici les pistes que nous avons relevées après avoir testé une dizaine d’outils, notamment Artifact, Informed, Feeeed, Apricot, Gistreader, Readwise Reader, etc.
Se libérer des réseaux sociaux en s’en inspirant
L’ambition la plus forte est celle d'Artifact. Il s'agit de « créer un réseau social de l’information ». Avec cette promesse de créer un espace dédié à l’information, où le public passerait autant de temps et serait aussi engagé que sur les réseaux sociaux, l'appli - disponible uniquement en téléchargement sur mobile - a fait l’objet de relais uniques à l’échelle internationale, tant dans la presse techno que dans la presse généraliste.
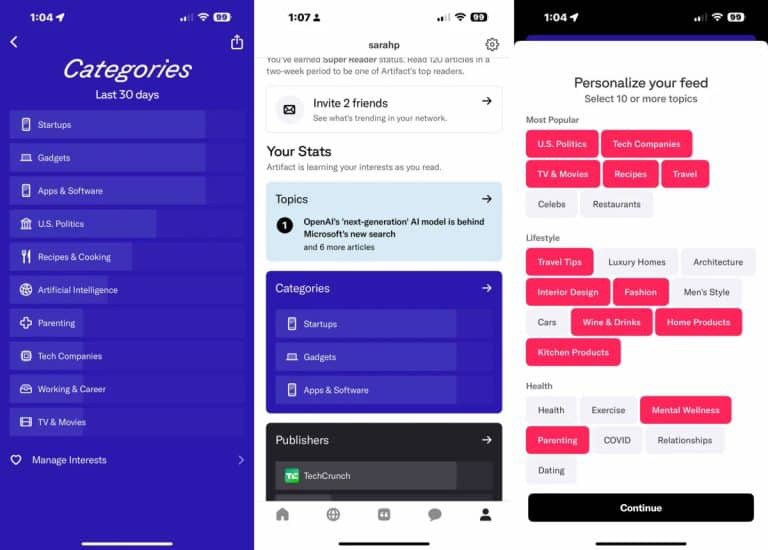
Figure 1. Configuration graduelle sur Artifact pour alimenter son algorithme, sous forme de Bonus à gagner.
La raison d’un tel engouement ? Ses fondateurs ne sont autres que ceux d’Instagram : Kevin Systrom and Mike Krieger. De quoi rendre Artifact, et tous ses lecteurs avec, un espace déjà plus trendy qu’Inoreader ou Feedly… avant même de l’avoir testé.

Déjà abonné ? Connectez-vous...
FOCUS IA : notre sélection pour résumer et interroger des vidéos YouTube

Pour ce nouvel article de « Focus IA », nous avons décidé de nous intéresser spécifiquement aux outils qui permettent de résumer et d’interroger des vidéos YouTube.
Nous avons identifié une vingtaine d’outils répondant à nos critères et nous les avons tous testés sur quatre vidéos : une vidéo d’actualité en français émanant d’un grand média français et une autre en anglais émanant d’un média américain, un webinaire d’une heure proposé par un éditeur de veille en français et enfin une vidéo tech en anglais recommandant plusieurs extensions ChatGPT.
Parmi la vingtaine d’outils, nombreux sont très décevants mais quatre sortent du lot et produisent des résultats intéressants pour les professionnels de l’information. Voici notre sélection !
Lire aussi :
Les meilleurs outils IA pour résumer et interroger les contenus de la veille (Netsources N° 164 - mai/juin 2023)
Notre sélection d’annuaires d'outils IA - Article en accès libre (Bases N° 414 - mai 2023)
Comment intégrer YouTube dans votre dispositif de veille (Netsources N° 157 - mars/avril 2022)
Nous avons testé Azure Video Indexer, un outil puissant pour les transcriptions automatiques de vidéos et podcasts (Bases N° 403 - mai 2022)
Attention : Même si ces outils « hallucinent » beaucoup moins que ChatGPT, ils ne sont pas exempts d’erreurs et approximations. Il est nécessaire de toujours revérifier les informations de ces outils si on souhaite les réutiliser par la suite.
Déjà abonné ? Connectez-vous...
Comment extraire gratuitement les commentaires des réseaux sociaux ?

Sur le Web, les commentaires publiés sous des articles, billet de blogs et sous les posts des réseaux sociaux peuvent parfois receler de véritables pépites mais ce sont des contenus difficiles à intégrer dans ses veilles et recherche d’information. En effet, on peut ponctuellement avoir besoin de plonger dans les commentaires sur les réseaux sociaux, par exemple pour une étude d’image, pour obtenir des informations complémentaires à l’article lui-même, pour y trouver des réponses, pour les analyser en vue d’une étude ou les sauvegarder en vue d’un usage futur.
Mais comment extraire les commentaires associés à un tweet sur Twitter, ou à un post sur Facebook, Instagram, LinkedIn, YouTube et les autres surtout quand ils sont nombreux et qu’on on ne dispose pas de budget ni d’un besoin suffisant pour acquérir une grosse plateforme payante ? Nous avons choisi ici l’angle des outils gratuits ou peu onéreux car l’extraction de commentaires ne représente souvent qu’un besoin ponctuel pour les professionnels de l’information et ne justifie donc pas l’acquisition d’une plateforme très onéreuse.
C’est ce que nous avons exploré dans cet article en testant différentes méthodes et outils et en vous proposant la meilleure issue de nos tests.
Lire aussi :
Comment surveiller Twitter après la fermeture en cascade des outils dédiés ? (Bases N° 413 - avril 2023)
Réussir à utiliser LinkedIn pour la veille et la recherche d’information (Netsources N° 158 - mai/juin 2022)
Veille Instagram : quoi, comment, pour quoi faire ? (Netsources N° 158 - mai/juin 2022)
Comment intégrer YouTube dans votre dispositif de veille (Netsources N° 157 - mars/avril 2022)
Facebook : toutes les clefs pour ouvrir ce coffre bien fermé à la veille ou la recherche (Netsources N° 158 - mai/juin 2022)
La méthode
Nous avons choisi de tester les méthodes et outils à partir des réseaux sociaux suivants :
- YouTube
À chaque fois, nous avons testé les outils sur des publications qui avaient une centaine de commentaires.
Les différentes méthodes et outils pour extraire des commentaires des réseaux sociaux
Le bon vieux copier-coller : une mauvaise idée
La méthode la plus simple et ne nécessitant pas l’utilisation d’outil externe consiste tout simplement à se positionner sur le post qui nous intéresse puis de copier-coller dans un fichier texte (Word) ou tableur (Excel par exemple) l’ensemble des commentaires.
Notre avis
Point positif, c’est la seule méthode qui ne nécessite pas l’usage d’outils externes. Cela peut fonctionner, mais c’est très chronophage quand il y a beaucoup de commentaires et il y a un très gros travail de reformatage pour réussir à obtenir des données véritablement exploitables. On ne recommandera pas cette méthode.
Les outils d’export depuis les réseaux sociaux
Passons maintenant aux outils dont le rôle principal est justement d’exporter les commentaires depuis les réseaux sociaux.
Certains sont multi-réseaux sociaux (sauf pour LinkedIn) comme Export Comments ou Comment Picker.
On trouve également des outils spécialisés sur l’exportation de commentaires depuis un réseau social spécifique :
- Pour Facebook : FB Comments Extractor
- Pour LinkedIn : LinkedIn comment Exporter mais limité à dix commentaires par fichier dans la version gratuite. Il faut ensuite payer entre 5 à 10$/mois
- Pour Instagram : Exportgram, IG Comment export, Instaloadgram ou encore Youtogift.
- Pour YouTube, YouTube Comments Downloader ou encore YouTube comments Scraper
On notera que la fin de la gratuité de l’API Twitter a mis un coup d’arrêt à la plupart des outils d’export pour ce réseau et il n’en reste aujourd’hui que très peu, souvent payants.
Déjà abonné ? Connectez-vous...
Les nouveaux outils de dataviz pour explorer la littérature scientifique

Il y a quelques années, on avait pu voir émerger des outils d’exploration des réseaux de citations des articles scientifiques. Ces outils s’avèrent très utiles pour trouver des articles scientifiques pertinents que l’on n’aurait pas forcément identifiés lors d’une recherche par mot-clé classique et sont donc complémentaires aux moteurs académiques.
Parmi cette première génération d’outils, il existait deux grandes catégories : ceux qui étaient visuels proposant donc une représentation graphique, et ceux qui étaient uniquement textuels
Voir notre article « La recherche de citations et de références boostées par l’IA et les “open citations” », Bases N° 369 - avril 2019.
Si les outils textuels ont bien résisté et ont aujourd’hui une place de choix dans le paysage de l’IST, les outils visuels n’ont pour la plupart pas eu le même destin. Parmi les outils de dataviz de première génération, on comptait des acteurs comme Citigraph, Yewno ou encore Citation Gecko, qui ont tous fermé leurs portes. Dans cette catégorie, seul VosViewer continue sa route et a été intégré très discrètement au moteur académique Dimensions.
Au cours des deux dernières années, une nouvelle génération d’outils visuels d’exploration des réseaux de citations est apparue, avec une petite dizaine d’acteurs cette fois-ci, toujours portée par l’amplification du mouvement de l’open (open access et open citations) dans le monde académique.
Dans cet article, nous dressons un panorama de ces différents outils et de leurs spécificités. Nous les avons également tous testés pour évaluer leur performance et vous aider à faire le bon choix.
Tour d’horizon des nouveaux outils de dataviz appliqués à l’IST
Au cours des dernières années, nous avons pu noter l’apparition d’une petite dizaine d’acteurs proposant de rechercher et analyser les réseaux de citations des articles scientifiques façon dataviz. On retrouvera ces différents acteurs dans l’infographie en figure 1. À cette liste s’ajoutait CoCites, un outil intéressant lancé en 2020, mais qui a cessé de fonctionner suite au décès de son créateur.
Si au départ, tous les outils de ce type étaient entièrement gratuits, force est de constater que les modèles ont rapidement évolué. On a d’un côté des outils complètement gratuits, souvent des projets personnels réalisés sur le temps libre qui revendiquent leur appartenance au mouvement de l’open et s’engagent à rester gratuits et de l’autre des outils qui sont devenus des produits à part entière avec des équipes derrière et qui fonctionnent sur des modèles freemiums.
Déjà abonné ? Connectez-vous...
FOCUS IA : notre sélection d’annuaires d'outils IA - article en accès libre

On découvre chaque jour, dans la déferlante des applis, extensions et plug-ins, tout le potentiel de ChatGPT et de l’IA pour nos métiers de l’information. Malgré les réserves très compréhensibles que l’on peut avoir, on ne peut nier l’intérêt de ces puissants modèles d’intelligence linguistique pour l’ensemble des opérations de traitement des données qui sont pour partie le socle de la veille et de l’activité documentaire.
Nul doute que le professionnel de l’information doive évaluer tous les outils en fonction de leur apport technique et fonctionnel sur l’ensemble de la chaîne de valeur des opérations. Leur intégration conduit progressivement à l’optimisation, voire le ré-engineering, des processus internes.
● Face aux enjeux, nos méthodologies et recommandations d’outils dans BASES et NETSOURCES intègrent de plus en plus les contributions des premières IA commercialisées. À titre d'exemple : la « Revue des moteurs de recherche à l’heure de ChatGPT », Bases N°413 - avril 2023, et notre prochain NETSOURCES dédié à ChatGPT et autres outils d'IA.
● Nous consacrerons désormais notre rubrique ACTUALITES à l’exploration des outils «du moment» dans un domaine fonctionnel donné, afin de sortir des discours euphoriques et faire émerger ceux qui nous paraissent les plus prometteurs dans un contexte incertain.
Nous avons décidé de commencer cette nouvelle série d’articles par les nouveaux annuaires IA car c’est une des portes d’entrée de choix vers les nouveaux outils dopés à l’IA générative. Parmi les nombreux annuaires sur le marché, nous en avons sélectionné quatre que nous avons jugés les plus pertinents.
Future Tools

Près de 1600 outils sont référencés par Future Tools. Le moteur de recherche est réalisé par Matt Wolfe, un développeur qui réalise des outils no code et du contenu autour de l’IA. Il a notamment une chaîne Youtube avec plus de 330 000 abonnés.
Modèle économique
L’accès au moteur est gratuit, mais on peut offrir si on le souhaite un Burrito au créateur du site. Chacun peut soumettre un outil gratuitement et le site n’accepte aucune forme d’affiliation. Chaque outil est approuvé individuellement, manuellement.
Matt Wolfe explique que son annuaire a commencé sous forme d’une liste Google Sheet fin 2021/début 2022, puis il a construit un site pour son usage personnel, avant de le partager sur les médias sociaux et d’ajouter une rubrique « Actualités ». Aujourd’hui les descriptions des outils et les actualités sont collectées par une IA, puis vérifiés et publiés par lui-même « AI generated, but human-curated ».
Recherche et filtres
Les outils peuvent apparaître par ordre de popularité (chacun peut voter pour un outil), par ordre alphabétique du nom ou par date de l’ajout dans l’annuaire. On aime particulièrement la pertinence des quelques 29 catégories (Text to Speech, AI Detection, Research, Prompt Guides) auxquelles on peut ajouter le filtre « gratuits/Freemium/Payant », mais aussi « Open Source/GitHub/Google Colab ». Quelques 100 outils sont ainsi référencés, rien que pour la recherche ! Dommage qu’aucun effort ne soit fait pour hiérarchiser les résultats.
Alertes et veille
On peut se tenir informé régulièrement via la newsletter (voir ci-dessous) ou créer le flux RSS de la page des derniers outils indexés, (avec Inoreader par exemple).
Autres contenus et fonctionnalités
Sa newsletter (plus de 100 000 abonnés, sans publicité), va droit au but. Elle est structurée ainsi : cinq outils (IA) innovants, trois articles d’actualité, trois vidéos inspirantes et une nouvelle façon de gagner de l’argent avec l’IA. Le site propose aussi un glossaire, très utile actuellement pour mieux comprendre les subtilités de l’IA.
WikiAITools
![]()
À l’heure où nous écrivons, près de 12 000 outils sont référencés sur WikiAITools. Le site, qui se veut « le plus large portail d’outils IA » a été rapidement créé en mars 2023 par Carter Wang, entrepreneur américain depuis une quinzaine d’années dans le milieu de la tech.
Modèle économique
La présentation du site mentionne « une équipe de développeurs et d’entrepreneurs » qui semble davantage conçu pour créer des opportunités commerciales autour de leur cœur d’activité : la création d’outils à base d’IA.
Recherche et filtres
Avec près de 200 catégories, il est difficile d’être plus exhaustif ! Mais si elle peut donner des idées de ce qu’il est possible de faire avec ces nouveaux outils, cette liste perd en lisibilité ce qu’elle gagne en exhaustivité. Chaque vignette/visuel mentionne rapidement si l’article est gratuit ou payant, mais il n’y a pas de filtre a priori, ce qui est dommage, surtout avec autant d’outils listés !
Il n’est pas possible d’uploader ou de soumettre des outils, il semble que ce soient les créateurs du site qui choisissent eux-mêmes les outils publiés, sans préciser si l’indexation est gratuite ou pas.
Alertes et veille
Pour suivre l’actualité des nouveaux outils, on peut consulter la rubrique « New Tools », mais surtout, on créera un flux RSS de la rubrique ou même d’une catégorie d’outils (elles ont l’avantage d’être près précises).
Autres contenus et fonctionnalités
Le site étant pensé pour un gain de notoriété des fondateurs, on imagine que le blog est là pour maximiser le SEO. Et de fait, l’équipe ne ménage pas ses efforts car elle a publié le premier mois un article tous les deux jours. Au final, après quelques jours de pratique, on lui préfèrera l'annuaire FuturePedia, exclu au départ pour son manque de transparence mais bien plus pertinent dans l'analyse des outils, fort d'une commuauté importante et d'une chaîne Youtube importante.
ToolScout.ai

ToolScout.ai est un annuaire dédié aux outils basés sur l’IA qui a été lancé au début de l’année 2023. Plusieurs centaines d’outils y sont référencés et l’annuaire est mis à jour quasi-quotidiennement. Même si le site n’indique pas qui est à l’origine de l’outil et l’alimente, nous avons réussi à identifier un certain Joshua Molinare.
Modèle économique
L’annuaire est accessible gratuitement et tout le monde peut soumettre de nouveaux outils à intégrer. Le site propose aux créateurs de mettre en avant leurs outils sur la page d’accueil pour un coût de 100$. Les outils ayant payé pour y être mieux référencés sont indiqués par une icône « Boosted » ou une couronne en or.
Recherche et filtres
L’annuaire dispose d’un moteur dont nous déconseillerons l’utilisation. En revanche, il propose un système de tags (comme Search Engine, Writing, marketing, SEO, etc.) et de filtres par prix (gratuit, payant, freemium, sur liste d’attente, open source, etc.) pour identifier des outils par catégories.
Alertes et veille
Pour détecter les nouveaux outils ajoutés à ToolScout.ai, il n’existe malheureusement pas d’alertes.
Deux possibilités s’offrent à nous : mettre sous surveillance (avec un outil ou service de surveillance de pages) cette l’URL suivante qui recense les derniers outils ajoutés ou s’abonner au compte Twitter de l’annuaire qui indique les nouveaux outils ajoutés.
Autres contenus et fonctionnalités
On peut se connecter à ToolScout avec son compte Google et on a alors la possibilité de bookmarker et évaluer (avec des étoiles) les outils. Pour chaque outil, on peut également savoir combien de personnes l’ont mis dans leur bookmark, ce qui peut être un signe de popularité et d’intérêt.
L’outil propose également une page de « News », avec des articles sur le thème de l’IA et qui est mise à jour très régulièrement. Si on a connecté son compte Google, on reçoit alors une newsletter régulière avec les dernières actualités.
AITools.fyi

Cet annuaire a été lancé en janvier 2023 par Rishit Patel, un développeur indien basé au Canada.
Modèle économique
L’annuaire est accessible gratuitement mais fait payer le référencement des outils aux éditeurs (10$). Il existe également des moyens d’être encore plus visible en payant plus cher pour être affiché sur la première page et en affichant des publicités sur différentes pages du site. La distinction entre les outils qui ont payé et les autres n’est pas très claire sur ce site.
Recherche et filtres
L’annuaire dispose d’un moteur de recherche simple et de nombreux tags pour filtrer facilement les résultats par type d’outil comme Video Generation, summarizer, etc et modèle économique (gratuit, payant, freemium).
Alertes et veille
Il n’existe pas de fonctionnalité d’alertes mais une page « Recently added » que l’on pourra mettre sous surveillance avec ses outils de veille classiques. Le site propose également une newsletter régulière qui signale certains outils. Attention, là encore la newsletter mêle contenus sponsorisés et organiques.
Autres contenus et fonctionnalités
L’annuaire utilise un modèle à la Reddit où les internautes peuvent mettre des upvotes, c’est-à-dire l’équivalent de likes sur d’autres réseaux sociaux, ce qui peut donner une première indication sur la valeur et l’intérêt de l’outil. On appréciera également que pour chaque outil, l’annuaire nous propose plusieurs alternatives.
L’annuaire propose une page « Deals » qui rassemble des codes promo à utiliser sur certains outils payants ou freemiums référencés dans l’annuaire.
Enfin, le site est lié à un autre site du même créateur appelé « AI of the Day » avec chaque jour cinq outils mis en évidence, une sélection d’actualités sur le thème de l’IA et une autre sélection des outils les plus tendances de la semaine.
Comment identifier les dispositifs d’aides publiques et privées

La recherche de financements est souvent au cœur des préoccupations des entreprises, des instituts de recherche et des universités, ainsi que des associations.
Réussir à identifier des financements demande une rigueur certaine car il existe des milliers de dispositifs d’aide à l’entreprise en France, et la même information est relayée par beaucoup de moteurs de recherche et quelques listes de sources à ne pas omettre.
Nous vous proposons ici une démarche méthodes/outils complète pour agir de façon structurée et la plus exhaustive possible dans la recherche de financements.
Poser les bonnes questions à son client
Le professionnel de l’information n’est pas forcément un expert en financements, et, un brief client sur les questions financières demande un haut niveau de confiance. Car les types d’aides sont divers et les filtres des moteurs de recherche touchent le cœur de la stratégie financière d’un client puisqu’ils concernent les sources et la nature des financements (emprunts bancaires, partage de capital, subventions par quel type d’organisme, avec ou sans apport, etc.).
En cas de création ou de reprise d’entreprise, on pourra s’aider de ce questionnaire de Bpifrance, qui commence par distinguer les financements pour une étude de faisabilité/un prototype, le projet dans son ensemble, un besoin de trésorerie, des investissements.
Trouver les mots-clés… efficaces !
Que la recherche soit sous la forme de requête booléenne ou de prompt (une consigne sur une IA), elle nécessite des mots clés pour guider vos recherches, du général au particulier.
Vous pourrez commencer par préciser :
● la nature du demandeur, comme « institut de recherche », « entreprise » ;
● la nature de l’aide : « aides publiques », « aides privées » ou « mixtes » ;
● le type de besoin : « micro crédit », « subvention », « prêt », avance, allègement de charges, crédits d’impôt, etc ;
● le niveau de l’aide demandée : département/régional, national, européenne ;
● le domaine de financement : « innovation », « création ou reprise d’entreprise », « transition énergétique », « R&D », « Recherche développement innovation (RDI) », etc ;
● l’objectif du financement : recherche fondamentale, recherche appliquée, aide à la connaissance, etc ;
● le secteur du demandeur : agriculture bio, high tech, robotique.
Mais surtout… il est nécessaire de rechercher des « moteurs de recherche », des « portails », voire des « bases de données », sous peine de se noyer dans les initiatives des milliers de dispositifs/solutions et d’organismes de financements… et de leurs intermédiaires !
Guides et filtres des moteurs de recherche fournissent aussi de très bons mots-clés, y compris pour effectuer des recherches dans la presse, comme « micro-crédit », « prêt bancaire », « crédit vendeur », voire « exonérations ».
Sources et outils
Déjà abonné ? Connectez-vous...
Que valent les outils de reconnaissance faciale pour la veille image ou l’investigation ?

À côté des outils de reconnaissance faciale payants créés par Clearview, Thales ou Amazon, des moteurs de recherche faciale sont accessibles gratuitement sur le web, et à tout public. Mais que peut-on en tirer dans un contexte de recherche et de veille professionnelle ?
On pourrait penser que la reconnaissance faciale n’est rien d’autre que de la recherche d’image inversée, consacrée aux visages. Il existe d’ailleurs une option « Face » dans Google Images. Mais à la lecture des résultats, on comprend que l’outil n’a vraisemblablement pas été conçu pour prendre en charge la reconnaissance faciale individuelle.
Surtout, il s’agit de deux technologies différentes, aux usages différents :
- La recherche d’image inversée utilise un algorithme de recherche d’image permettant de comparer une image uploadée sur un moteur de recherche à celles qui sont disponibles publiquement sur internet. Elle est donc utilisée pour trouver la source d’une image et/ou en vérifier l’authenticité, ce qui permet à un professionnel de l’information de vérifier la source et la fiabilité d’une information. Appliquée à une personne en l’absence de données d’identification, cette recherche nécessite de se fier à la légende de la photo, si légende il y a, pour identifier la personne.
- La reconnaissance faciale utilise elle aussi des algorithmes de recherche, mais également des données biométriques (écartement des yeux, couleur de peau, etc.). Les photos auxquelles l’image source est comparée peuvent provenir du web ouvert (sites d’actualités, de mariages, blogs, etc.), mais aussi, en théorie, de bases de données. Contrairement à la recherche inversée, ce sont des visages identifiés par l’IA de l’outil qui remontent dans les résultats de recherche.
Au-delà de la comparaison d’images, la reconnaissance faciale permet ainsi d’identifier une personne en recherchant à partir de n’importe quelle image… similaire ou non, ou même des images prises à des années d’intervalle.
C’est pourquoi elle est aujourd’hui très prisée pour identifier des personnes dans des domaines tels que la sécurité (lutte contre la fraude), la biométrie (accès biométriques) ou la publicité (e-réputation). Elle soulève toutefois des questions en matière de protection de la vie privée et de la sécurité des données personnelles, raison pour laquelle son utilisation est réglementée en Europe, et même interdite dans certaines villes américaines.
Dans ce contexte, la reconnaissance faciale peut-elle profiter à un professionnel de la veille ? Pour répondre à cette question, nous avons exploré cinq outils gratuits ou à faible budget, que l’on a classés en trois usages.
Déjà abonné ? Connectez-vous...
Revue des moteurs de recherche à l’heure de ChatGPT

Le bouleversement de ce début d’année 2023, c’est bien évidemment le lancement grand public de ChatGPT et plus largement la course à l’intégration de l’IA générative dans tous les outils du quotidien et du monde professionnel.
Les moteurs de recherche Web dans leur ensemble se sont tous précipités pour intégrer cette dimension à leurs moteurs, certains intégrant directement GPT-3 ou 4 comme Bing et d’autres préférant utiliser d’autres modèles.
Cette intégration de l’IA générative et conversationnelle dans les moteurs apporte sans conteste une dimension nouvelle à la recherche d’information sur le Web.
Mais est-ce que cela améliore réellement les moteurs Web ? Cela permet-il de trouver plus rapidement de l’information, de trouver des informations qui n’arrivaient pas à émerger dans les moteurs de recherche, d’explorer plus en profondeur la fameuse longue traîne ?
Lire aussi :
Les moteurs gratuits, c’est fini (avril 2023)
L’actu du Veilleur : plein phare sur l’IA (Bases N° 411 - fev 2023)
Quels outils utiliser pour bénéficier de ChatGPT ? (Bases N° 410 - jan 2023)
Nous avons testé Kagi Search, un nouveau challenger de Google (Bases N° 407 - oct 2022)
Presearch permet de chercher depuis la localisation de son choix (Bases N° 410 - jan 2023)
Nous avons testé Neeva, le moteur qui pourrait remplacer Google chez les pros de l’info (Bases N° 406 - sept 2022)
C’est ce que nous avons voulu explorer dans cet article en proposant tout d’abord un tour d’horizon des solutions d’IA génératives qui ont été intégrées aux moteurs de recherche ces derniers mois - et ils sont nombreux - et en évaluant ensuite ce que cela change en matière de performance et d’efficacité quand on recherche de l’information sur le Web. Alors que Google restait indétrônable depuis des années pour les professionnels de l’information, est-ce que l’apparition de ces assistants rebat les cartes et faut-il revoir sa stratégie sur les moteurs de recherche ?
Nota Bene
L’apparition de ChatGPT auprès du grand public et plus largement des IA génératives et la multiplication des outils qui utilisent ces technologies pour de multiples usages constituent un sujet extrêmement vaste. Pour cet article, nous avons choisi un angle bien précis : l’intégration d’IA génératives par les moteurs de recherche classiques déjà présents sur le marché et le bouleversement que cela peut représenter pour la recherche d’information.
Comprendre les IA génératives pour comprendre leur place dans les moteurs
ChatGPT avec son modèle GPT-3 et 4 : une IA générative parmi d’autres
Comprendre l’intégration de l’IA générative dans les moteurs nécessite d’avoir certains éléments de contexte en tête. C’est donc ce par quoi nous commencerons cet article.
OpenAI avec le lancement de ChatGPT a réussi l’exploit d’éclipser tous les autres acteurs travaillant sur les sujets de l’IA générative et à imposer son produit sur le marché. Mais en réalité, cela fait des années que plusieurs acteurs et notamment les Gafams travaillent sur le développement d’IA conversationnelles et génératives qui pourraient venir enrichir les moteurs de recherche.
En 2017 déjà, nous avions assisté à la conférence « Search Solutions » à Londres où l’un des Research Scientists de Google était venu expliquer que l’un des axes de développement de Google était alors la recherche conversationnelle.
Voir l’article « De la recherche classique à la recherche conversationnelle » (Bases N° 354 - décembre 2017) que nous avions écrit à l’époque.
On retiendra avec attention que ce même intervenant avait alors évoqué les conditions nécessaires pour la mise en place opérationnelle d’un système de recherche conversationnelle au sein des moteurs :
- le système doit permettre d’expliciter le besoin réel de l’utilisateur ;
- le système doit révéler à l’utilisateur ses capacités et son corpus afin de lui montrer ce qu’il peut faire ou non ;
- le système et l’utilisateur peuvent chacun prendre l’initiative d’intervenir quand cela est utile ;
- des éléments de mémoire doivent être introduits. L’utilisateur doit pouvoir faire référence à des choses qu’il a dites plus tôt dans la conversation ou dans d’autres conversations ;
- le système doit être capable d’apporter si besoin des ensembles d’information complémentaires et de les agréger.
En 2017, aucun système n’arrivait à réunir les différentes conditions pour pouvoir l’implémenter dans le moteur de recherche. Dans les années qui ont suivi, Google a continué à intervenir dans différentes conférences sur le thème de la recherche conversationnelle, mais cela n’avait pas été intégré dans des produits grand public, tout simplement parce que les conditions n’étaient toujours pas réunies. Fin 2022, aucun acteur (et pas seulement Google) travaillant sur le sujet n’avait encore jugé les technologies suffisamment matures pour les lancer auprès du grand public.
Mais OpenAI est passé par là et a pris tout le monde de court en mettant sur le marché un produit qui ne remplit pas toutes les conditions, mais qui est impressionnant. Le coup de maître (ou l’inconscience selon les points de vue) d’OpenAI à « dégainer en premier » et éclipser tous les autres acteurs marque, dans tous les cas, un tournant. Et un retour en arrière est plus qu’improbable. Face à ce lancement, tous les moteurs de recherche ou presque ont voulu sauter dans le train en marche : Google pour ne pas donner l’impression de ne plus être le leader du « Search » sur le Web et les autres moteurs pour avoir enfin une chance de surpasser Google.
Déjà abonné ? Connectez-vous...
L’actualité mouvementée des réseaux sociaux et l’impact sur le veilleur

Des changements dans les flux algorithmiques qui modifient la veille
Les réseaux sociaux proposent pratiquement tous par défaut un flux d’information algorithmique que l’utilisateur peut faire défiler pour trouver des contenus susceptibles de l’intéresser.
Pendant longtemps, le flux des utilisateurs des réseaux sociaux était constitué essentiellement de contenus publiés par ses amis, les personnes ou comptes suivis et agrémentés de quelques contenus sponsorisés. Comme tout flux algorithmique, il s’agit d’une sélection de contenus et non de l’intégralité des contenus publiés par ses contacts.
Si la notion de sélection ne change pas, les contenus proposés, eux, sont en train de changer et on voit de plus en plus de contenus émanant de personnes en dehors de notre réseau.
Lire aussi :
Comment récupérer des flux RSS sur les réseaux sociaux ? (Netsources N° 159 - juil/août 2022)
Comment surveiller TikTok : un réseau social atypique pour le veilleur (Netsources N° 157 - mars/avril 2022)
Facebook : toutes les clefs pour ouvrir ce coffre bien fermé à la veille ou la recherche (Netsources N° 158 - mai/juin 2022)
Reddit, réseau social méconnu en France, mais véritable atout pour la recherche spécialisée (Netsources N° 158 - mai/juin 2022)
Réussir à utiliser LinkedIn pour la veille et la recherche d’information (Netsources N° 158 - mai/juin 2022)
Search Quiz : Êtes-vous à jour dans votre veille réseaux sociaux
Veille Instagram : quoi, comment, pour quoi faire ? (Netsources N° 158 - mai/juin 2022)
Sur Twitter par exemple, le flux d’information que l’on voit sur sa page d’accueil appelé « Pour vous » contient de plus en plus de contenus émanant de comptes que l’on ne suit pas. Et cela ne va pas aller en s’améliorant, car Elon Musk vient tout juste d’annoncer que seuls les comptes ayant souscrit un abonnement payant à Twitter Blue pourront apparaître dans le flux « Pour vous ».
Cela ne semble pas encore mis en place, car nous sommes toujours capables de visualiser dans ce flux des contenus émanant de comptes que nous suivons et qui n’ont pas souscrit d’abonnement, mais cela devrait changer très prochainement.
LinkedIn vient de faire une annonce similaire et s’apprête à bouleverser le fil d’actualité en y introduisant des publications suggérées par son IA, en fonction des centres d’intérêt de l’utilisateur, y compris en provenance de profils en dehors de son réseau.
Impact sur la veille
Il faut donc avoir ces évolutions bien en tête quand on fait de la veille directement dans les plateformes des réseaux sociaux. On va avoir d’un côté des flux algorithmiques qui vont permettre d’aller toujours plus loin dans la « veille radar » en détectant des contenus en dehors son champ et de ses sources habituelles et de l’autre des flux non algorithmiques (l’équivalent du flux « Abonnement » sur Twitter ou du classement « récent » sur LinkedIn) qui correspondent à la « veille cible » avec des contenus émanant quasi exclusivement de sources/comptes préalablement identifiés lors de son sourcing. Les deux types de flux ont leur utilité et seront donc de plus en plus différents l’un de l’autre, mais de plus en plus complémentaires.
Une course aux certifications payantes qui appelle à une vigilance accrue en matière de sourcing
Une des grandes tendances de ces dernières semaines sur les réseaux sociaux, c’est la course aux certifications payantes, ces petits badges de couleur apposés aux comptes sur les réseaux sociaux.
Déjà abonné ? Connectez-vous...
Comment surveiller Twitter après la fermeture en cascade des outils dédiés ?

Il y a quelques mois maintenant, Twitter avait annoncé la fin de son API gratuite au profit d’une API payante. Après quelques mois de flottement, Twitter n’a finalement pas coupé l’accès à son API à la date prévue et a tout même annoncé garder une API gratuite allégée pour pouvoir publier du contenu directement sur Twitter. En revanche, impossible pour l’utilisateur de collecter, récupérer et analyser les contenus. Il y a quelques semaines, le couperet est finalement tombé, l’accès à l’API gratuite a été révoqué pour tous les acteurs qui l’utilisaient.
Si au départ, tous les acteurs proposant des fonctionnalités de veille, de création de flux RSS, d’analyse pour Twitter se voulaient rassurants, l’optimisme n’a été que de courte durée. Et en quelques jours seulement, on a assisté à une véritable hécatombe avec des fermetures et des retraits de fonctionnalités en cascade.
Les agrégateurs de flux RSS Feedly et Inoreader ont annoncé le retrait de leurs fonctionnalités de surveillance de Twitter. Une majorité de plateformes de veille classiques ont été dans l’obligation de faire de même (à l’exception des plateformes de social media monitoring). Les petits outils de création de flux RSS qui avaient une option spécifique pour Twitter sont également concernés. Et les nombreux outils uniquement centrés sur Twitter comme Twitterdaily, Tweetbeaver ou encore Hoaxy n’ont eu d’autre choix que de fermer boutique.
À ce stade, il n’est pas question d’abandonner toute tentative de faire de la veille sur Twitter. Les multiples réseaux sociaux qui se sont positionnés comme des alternatives à Twitter n’ont pas encore trouvé leur public et de nombreux internautes continuent de publier des contenus pertinents pour la veille sur Twitter.
Quelles méthodes et outils nous reste-t-il pour faire de la veille sur Twitter ? C’est ce que nous avons exploré dans cet article.
Lire aussi :
Le guide ultime de la veille et la recherche d’information sur Twitter (Netsources N° 158 - mai/juin 2022)
Réussir à utiliser LinkedIn pour la veille et la recherche d’information (Netsources N° 158 - mai/juin 2022)
Reddit, réseau social méconnu en France, mais véritable atout pour la recherche spécialisée (Netsources N° 158 - mai/juin 2022)
Veille Instagram : quoi, comment, pour quoi faire ? (Netsources N° 158 - mai/juin 2022)
Comment intégrer YouTube dans votre dispositif de veille (Netsources N° 157 - mars/avril 2022)
Comment surveiller TikTok : un réseau social atypique pour le veilleur (Netsources N° 157 - mars/avril 2022)
Surveiller Twitter via des flux RSS : Nitter, le seul survivant
Du côté des outils gratuits ou bon marché, nous avons eu la bonne surprise de découvrir que Nitter, un outil qui permet de naviguer sur Twitter sans compte et de récupérer des flux RSS fonctionnait toujours.
Certaines fonctionnalités ont cessé de fonctionner, mais d’autres continuent d’être utilisables, car il utilise une API « non officielle » (donc non pérenne). C’est le cas notamment de la fonctionnalité permettant de récupérer un flux RSS sur un compte Twitter ce qui permet d’être alerté à chaque fois qu’un nouveau contenu est publié par ce même compte sur Twitter (Cf. Figure 1. Récupération d’un flux RSS sur Nitter).
Nous avons testé et le flux RSS se met bien à jour. En revanche, il n’est plus possible de récupérer un flux RSS depuis une requête par mot-clé sur Twitter, ce qui était pourtant offert par le passé.
Déjà abonné ? Connectez-vous...




















